Object Detection
📌 Object Detection
- '어떤'물체가 '어디'있는지 파악하는 작업
- classfication + box localization
- 자율주행 , OCR 등의 분야에 적용
📌 One stage detector VS Two stage detector

| One -stage Detector | Two stage detector |
| localization 과 classification을 한 번에 진행 | localization 진행 후 , classfication 진행 |
| 빠르지만 성능 저하 | 성능은 좋지만 느림 |
| Yolo , SSD , RetinaNet | R-CNN , Fast R-CNN, Faster R-CNN |
📌 Two-stage detector : R-CNN family
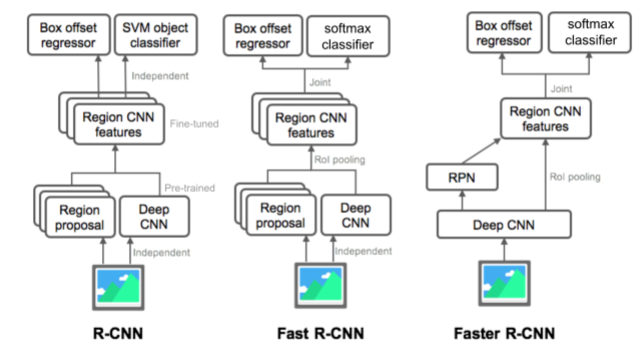
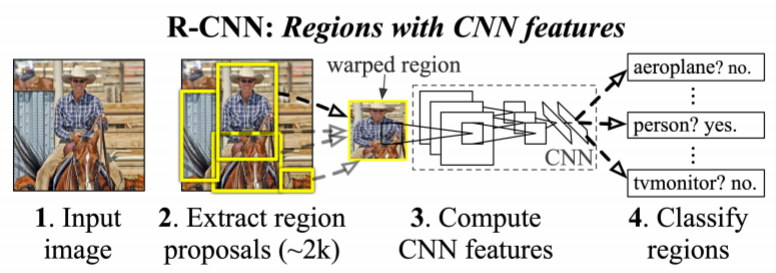
- R-CNN
- Directly leverage image classification networks for object detection
- Selective search 알고리즘을 이용하여 ROI proposal
- ROI마다 CNN을 거쳐 학습돼 feature vector 생성
- SVM분류기를 이용하여 분류
- end-to-end training ❌
- ROI마다 conv를 거치기 때문에 속도가 너무 느림 (ROI개수만큼 학습이 일어남)
- Fast R-CNN
- Recycle a pre-computed feature for multiple object detection
- CNN을 original image에 맞춰 학습
- Selective search를 통해 만들어진 ROI를 feature map에 projection 시킴 : RoI poooling
- RoI feature vector 를 이용하여 classification branch , bbox regressor branch를 통해 예측
- CNN을 한 번만 학습시켜도 되기 때문에 속도가 RCNN에 비해 빨라짐
- SVM이 아닌 FC layer를 통해 분류. 하지만 selective search를 사용해 end-to-end ❌

- Faster R-CNN
- End-to-end object detection by neural region proposal
- RPN이라는 네트워크를 통해 region proposal도 neural network로 해결
- bounding box의 reference가 되는 'Anchor box' 도입
- original image에 대해 CNN 학습 후 RPN에서 Anchor box를 참조하여 RoI 생성
- Faster RCNN과 branch는 동일
- Selective search를 RPN으로 대체해 end-to-end training ⭕

📌 Single Stage detector
- YOLO
- bounding boxes + confidence 계산
- 각 gride에 대해 class probabililty 계산
- bounding box의 중심이 해당하는 grid의 class가 box가 인식한 객체의 class가 됨
- CONV를 거쳐 7x7x30 tensor 생성 -> grid 별 box 2개 + class prob , box별 좌표+object score
- Fatser RCNN과 비교했을 때 mAP 7↓ , FPS 3배↑

- SSD
- multi-scale outputs with multiple feature maps (작은 물체는 탐지못하는 YOLO의 단점 보완 )
- Anchor box 개념 사용 -> 하나의 물체를 여러 sclae로 detection
- Feature extract 과정에서 Multi scale로 Detection
- YOLO에 비해 성능,속도 모두 좋음

📌 RetinaNet with Focal loss
- One stage detector 의 문제 : Negative 와 Positive 간의 imabalance
- 영상 전체 위치에서 객체의 위치, 크기, 비율을 dense하게 샘플링
- 상대적으로 positive 는 적고 , 아무 의미 없는 negative 의 수가 압도적으로 많음 .
- 게으른 모델이 분류하기 쉬운 easy negative들만 학습
- YOLO에서는 이 문제를 해결하기 위해 P/N에 따라 loss에 가중치 부여
- SSD 에서는 이 문제를 해결하기 위해 N/P 의 비율을 3:1로 맞춰 학습

- Focal loss
- CE loss를 확장한 개념으로, Scaling factor $(1-p_{t})^{\gamma}$를 추가
- Down-weights easy samples : 쉬운 예제는 학습에 기여하는 정도를 낮춰줌
- 분류하기 어려운 예제들이나 , 잘못 분류 된 예제들에 대해서 집중
- focal loss 를 사용하면 easy exam일 때 기울기는 거의 0에 가깝고, hard exam일 때 기울기는 더 커짐

👉 loss가 정말 중요하구나,,,, ㅇㅂㅇ,,,,
- RetinaNet
- single model이지만 focal loss를 이용하여 two stage 보다 빠르면서 성능도 좋음
- FPN 구조에 cls/box branch를 추가한 모델
- FC layer 없이 convolution 만을 이용

📌 DETR : Detection with Transformer
👉 ViT 읽어보고, DETR 읽어보기! 동아리 10주차 논문으로 계획
다행?히도 RetinaNet , DETR 빼고는 다 읽어본 논문이라 큰 무리 없이 이해할 수 있었던 강의
다만 Focal loss 가 신기하다. 불량품의 비율이 현저하게 낮은 산업계에서 잘 써먹을 수 있을 거 같다.
CNN visualizatioin
📌 Visualization CNN
- 디버깅 툴로써 visualization tool 사용
- layer1 이후로는 채널 수가 많기 때문에 사람이 직관적으로 이해할 수 없어 굳이 하지 않음
- 모델 자체의 특성을 분석하는 Analysis of model behaviors , 특정 input에 대해 output이 나온 이유에 대해 분석하는 Model dicision explanation

'Naver Ai Boostcamp' 카테고리의 다른 글
| [DAY 35] Multi-modal & 3D Understanding (0) | 2021.03.25 |
|---|---|
| [DAY 34] Instance/Panoptic segmentation & Conditional generative model (2) | 2021.03.17 |
| [DAY 31] Image classfication1 & annotation data efficient learning (0) | 2021.03.13 |
| [Day 26] 특강 및 자율 공부 (0) | 2021.03.03 |
| [Day 25] GNN 기초 & GNN 심화 (0) | 2021.03.02 |