Instance/Panoptic segmentation
📌 Instance segmentation
- semantic segmentation + distinguishing instances
- 같은 클래스더라도 객체가 다르면 다르게 segmentation 해준다.
- 주로 object detection을 기반으로 함

- Mask RCNN
- RoI pooling으로 생기는 misalignmenta문제를 RoI Align을 사용하여 해결 ,
bilinear interpolation을 이용해 소숫점으로 맞춰줌 - Faster RCNN에 Mask branch 추가 : class 별 binary mask classfication 생성 -> cls결과에 따른 채널 사용
- backbone 모델에 FPN Network 추가
- keypoint detection도 가능
- RoI pooling으로 생기는 misalignmenta문제를 RoI Align을 사용하여 해결 ,

- YOLOACT(You Only Look At CoefficienTs)
- single stage network
- Mask prototype을 추출해서 사용
- Mask를 합성해낼 수 있는 여러 물체의 soft segmentation component : prototype
선형대수 관점에서 바라보면 Mask 를 선형결합으로 생성해낼 수 있는 basis 역할 - Prediction Head에서 각 프로토타입에 대한 계수 계산
- Mask Coefficients와 prototype의 선형결합을 이용
- Mask RCNN에서 class의 개수만큼 binary map을 만들었던 것과 다르게 basis와 그 계수만을 이용해 효율적으로 계산 가능

- YolactEdge
- Edge device에 올리기 위한 YOLOACT 소형화
- 이전 frame 중 keyframe에 해당하는 frame의 feature를 다음 frame에 전달해 계산량을 획기적으로 감소시킴
- 속도는 훨씬 빠르면서 성능은 비슷함
📌 Panoptic segmentation
- Instance segmentation은 thing만 구별 , stuff에 대한 정보X
- semantic segmentation은 stuff애 대한 정보 O, thing 에 대한 구별 X
- panoptic = instance + semantic : 객체에 대해 구별해서 segment하면서 stuff 에 대한 정보도 가짐

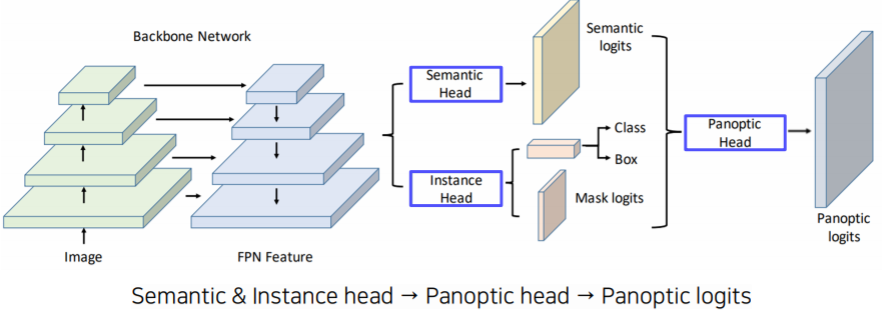
- UPSNet
- 내 눈에는 ,,, MaskRCNN에 semantic Head만 추가해준 거 같은데,,,,,
- semantic head의 결과물과 instance head의 결과물을 융합해 panoptic logits을 출력
- semantic head에서의 stuff(BG)에 대한 map은 그대로 panoptic의 stuff map
- Instance head를 통해 객체의 RoI 에 맞는 semantic head의 thing에 mask를 씌워 instance에 해당하는 panoptic logits 생성
- semantic head의 thing에서 RoI가 있는 부분을 제외한 나머지 부분은 unknown으로 인식. 모두 하나의 채널

📌 landmark localization
- keypoint detection, keypoint들의 좌표를 예측하는 태스크
- facial landmark localization , human pose estimation 등
- coordinate regression vs heatmap classfication
- coordinate regression : 간단하지만 부정확함
- heatmap classfication : 성능은 좋지만, 계산 비용이 크다 , 각각의 채널이 각각의 keypoint를 의미

- Hourglass network
- Unet과 비슷한 구조를 여러개 쌓은 구조
- downsampling을 통해 receptive field를 키우고, skip connection을 이용하여 low-level feature 참고
- skip connection 에서 Identity mapping이 아닌 conv를 거침 , concat이 아닌 add

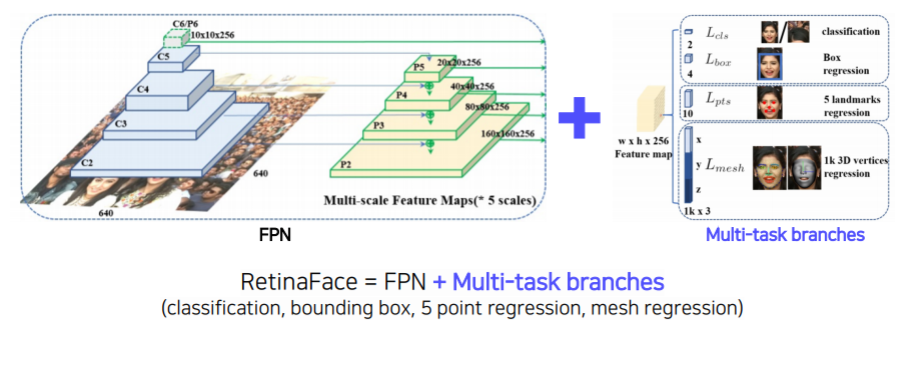
- RetinaFace
- FPN + Multi-task branches (cls , bbox , 5 keypoint detection , mesh regression )
- FPN으로 feature를 extract한 후 , 여러 가지 branch를 달아서 다양한 task 를 해결
- task는 조금씩 다르지만 , 얼굴에 대한 feature 를 extract 해야 하는 것은 동일!
multi branch의 모든 상황을 고려해 학습해야 하므로, 적은 데이터로도 성능을 볼 수 있으며 모델이 더욱 robust해질 수 있다는 학습시의 장점이 존재
💡 CV Trends : backbone + Target-task branches 로 다양한 응용
📌 Detecting object as keypoints
- CornerNet
- Non-anchor based : anchor box의 scale, ratio등을 정해주거나, 수천 개의 anchor box를 사용할 필요도 없음
- 점 2개 ( 좌측 상단의 점 , 우측 하단 점) 만으로 object detection 수행
- 성능보다는 "속도"에 초점을 맞춤
- hourglass networ를 backbone으로 사용

- CenterNet
- 1 : cornernet에 center까지 세 점을 예측 => 성능에 있어서 center가 중요하다
- 2 : center point, width , height 만으로도 bbox를 예측 가능 -> bbox 를 유니크하게 결정하기 위한 최소 정보
- 속도, 성능 모두 월등하게 좋음
- backobone도 여러가지로 사용 가능

Conditional generative model
📌 Conditional generative model
- 주어진 조건에 따라 확률분포에서 샘플링해 이미지를 생성
- Generative Model vs Conditional generative model
- Generative model : 랜덤 샘플 ⭕ , 사용자의 의도에 맞게 조작 ❌
- Conditinal generative model : 사용자의 의도에 맞게 조작 , 추가 정보를 통해 데이터 생성 과정 제어
- generator의 input으로 latent variable + condition

- super resolution : 저해상도 이미지가 주어졌을 때, 고해상도 이미지를 생성해냄
- Naive Regression model : mae , mse 같은 loss를 사용해서 더 단순하게 이미지 생성 & 학습

- regression model 보다 SRGAN이 더 좋은 이유
- MAE/MSE는 loss를 줄이는 데 집중 -> 최대한 안전하게 loss를 줄이기 위해 최대한 값들의 평균에 근사
- GAN loss는 "실제 있을 거 같은" 이미지를 생성하는데 집중
- ex ) 흰색 이미지와 검은 색 이미지가 있을 때 , mae/mse loss은 평균인 "회색"을 만듦 , 하지만 gan loss를 이용하면 실제로 존재하는 흰/검 이미지만 생성

- CGAN을 통해 pix2pixe , cyclegan 같은 Image translation GANs 탄생
📌 Image translation GANs
- Image translation : domain이 다른 image로 바꿔주는 것 ex) label -> street scene

- PIX2PIX
- Supervised 기법 : pair 이미지가 필요
- Total loss = Gan loss + L1 loss
- L1 loss 를 사용하는 이유
- GAN loss는 Ground Truth 와의 직접적인 비교 불가
- L1 loss를 사용하면 Ground Truth와 가깝게 만들 수 있게 됨
- GAN의 학습이 굉장히 불안정하기 때문에 L1 loss가 길잡이 역할을 해 학습을 안정시킴
- MAE loss만 사용시 이미지가 blurry 함 & GAN loss만 이용시 real하지만 , 실제 원하는 GT와는 너무 다른 모습


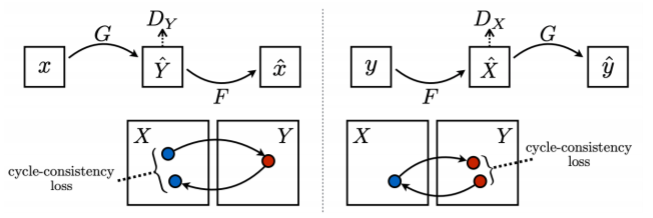
- Cycle GAN
- 실제 pair dataset은 희소 -> 1:1 대응관계가 존재하지 않는 non-pairwise dataset을 이용
- CycleGAN loss = bidirection GAN loss + Cycle-consistency loss
- Gan loss 사용 시 , 이미지 x에서 y로 가는 , y에서 x로 가는 서로 다른 generator model 2개가 필요
- GAN loss 만 사용 시 , mode collapse 문제 발생
- mode collapse : input과 상관 없이 낮은 loss를 가지는 하나의 output만을 가지게 됨 -> 바보 🥴
- Cycle-consistency loss 를 사용하여 해결 : style 만 보지않고 contents도 보존
- x와 g(f(x))가 얼마나 유사한지 (contents) 를 loss로 계산
- self-supervised 방식

📌 Perceptual loss
- train이 까다로운 GAN 대신 간편하게 high quality image 를 얻을 수 있는 방법
- GAN loss 는 pre-trained network가 필요 없어 아무 곳이나 적용할 수 있다는 장점이 있지만 , 학습과 코드가 상대적으로 어렵다.
- Perceptual loss 는 pretraiend network 가 필요하지만 train과 code가 간결하다.
- Image Transform Net 을 통헤 input 이미지로부터 변형된 output 출력
- output을 loss network에 입력해 중간 중간 feature를 추출해 style target , content target과 비교해 학습
- loss network(pre-trained network)는 freeze 로 학습 ❌ , Image Transform Net만 학습 됨

- Feature reconstruction loss
- transform 된 이미지가 원래 이미지 X의 정보(contents)를 유지하고 있는 지 확인
- 주로 content target으로 변형 전 이미지 X를 넣어줌
- pretrained network를 통해 뽑힌 feature들의 semantic contents 간의 L2 loss 계산

- Style reconstruction loss
- transform 된 이미지가 내가 원하는 스타일(style)을 잘 유지하고 있는 지 확인
- style target으로 내가 원하는 스타일의 이미지( ex. 고흐)를 넣어줌
- gram matrices : 공간정보 없이 feature map의 통계량(전체적인 style)만을 담고 있음
- 두 feature map을 C x (H*W)로 reshape 후 내적! => 채널 간 유사도 계산

📌 Various GAN applications
- DeepFake -> 이건 이상하게 쓰는 놈 잘못이지 🔥😩 -> defense mechanism에 대한 연구 진행
- Face de-identification & anonymization with passcode : 사람의 얼굴을 조금씩 수정해 개인의 사생활 보호
- video translation
- pose transfer
- videi-to-video translation
- video-to-game : controllable character
아 중간에 정리한 게 자꾸 날라간다... 화난다 🔥
ML 공부를 GAN때문에 시작했다고 해도 과언이 아닌데 이렇게나 GAN에 대해 아는 게 없을 줄 이야!
반 년 전 CYCLE GAN 논문을 처음 읽었을 때 기억이 새록새록 나는 하루였다
'Naver Ai Boostcamp' 카테고리의 다른 글
| [DAY 36] OMG 왜 안했누 (0) | 2021.03.26 |
|---|---|
| [DAY 35] Multi-modal & 3D Understanding (0) | 2021.03.25 |
| [DAY 33] Object Detection & CNN visualization (0) | 2021.03.17 |
| [DAY 31] Image classfication1 & annotation data efficient learning (0) | 2021.03.13 |
| [Day 26] 특강 및 자율 공부 (0) | 2021.03.03 |