내 기준 도입부가 굉장히 좋았던 강의
Image classfication1
📌 Why is visual perception important & what is computer vision
- AI 란? : 사람의 지능(인지, 지각, 기억, 이해, 사고 능력)을 컴퓨터 시스템으로 구현해놓은 것
- 사람의 지각 능력 중 "시각" => Computer Vision
- visual perception & intelligence를 구현 = Computer vision
- Color , Motion , 3D, Semantic-level, social perception 등이 존재
📌 Convolutional Neural Network
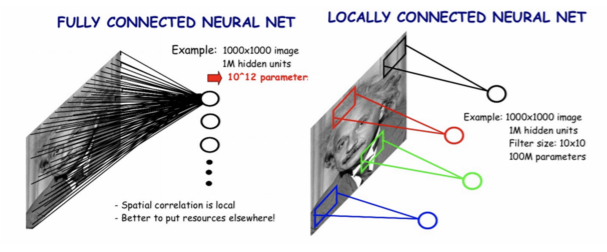
- Fully connected는 왜 이미지에 안 좋을까?
- 픽셀의 개수만큼을 input으로 가지게 되어 parameter의 수가 너무 많아진다.
- layer가 한 층으로 얕기때문에 평균 영상 이상의 표현력을 가질 수가 없다.
- 위치 정보를 고려하지 않는다. training 시와 test시의 차이가 생긴다.
그렇기 때문에 같은 이미지에서 픽셀들을 뒤죽박죽 섞어놔도 비슷한 성능이 나온다.
이미지 좌측에 원숭이가 있는 그림을 학습하고, 추론 시 주어진 이미지가 원숭이가 우측에 있는 그림이라면 FC의 우측픽셀들은 원숭이의 특징을 학습한 적이 없기 때문에 다른 이미지라고 생각한다.
즉, 너무 overfitting되는 거다.
❓ CNN과의 차이점으로,,, 이 부분에 대해서 CNN은 Translation Invariant라고 표현하는데, 그렇다면 fc는 translation variant인가? 구글에 검색해도 안나온다.

- 영상에서의 CNN
- Filter를 통해 local feature 학습
- Filter sharing 을 통한 parameter 수 감소
💡 CNN과 이미지가 찰떡궁합인 이유 + Ian GoodFellow의 CNN + christian wolf의 글 + invariance vs equivariance
+위 블로그 + 이안 굿펠로우의 책을 보고 공부한 점을 적는 거라서 틀린 부분이 있을 수도 있음!
1. weight sharing
CNN에서는 kernel이 sliding window형식으로 움직이면서 weight를 공유한다.
weight를 공유하면 위치에 상관없이 특징을 추출하기 위해서이다.
이미지의 특정 위치에서 학습한 파라미터를 이용해 서로 다른 위치에 있는 동일한 특징을 추출할 수 있게 된다.
FC에서는 weight를 공유하지 않아 동일한 특징이더라도 학습했던 위치와 다른 곳에서 발견되면 다른 특징으로 인식하게 된다.
그리고 또 파라미터의 수가 확연하게 줄어 연산량,메모리도 줄어든다.

2. sparse interaction
CNN은 local한 정보들을 보는데 이게 sparse interaction과 연관 있다.
kernel이 적용된 곳만 계산을 하고, kernel이 적용되지 않은 곳은 계산을 하지 않기 때문에 0으로 간주한다.
그러면 map의 대부분이 0이 되므로 이걸 sparse interaction이라고 표현하는 거 같다.
sparse는 overfitting을 방지하는 효과가 있다.
이미지의 특징들은 이미지 전체가 아니라 kernel만큼 일부 지역에 근접한 픽셀들로만 구성되기 때문에, 하나의 receptive field안에 들어오는 픽셀들끼리만 종속성을 가진다.

3. translation equivariance
To say a function is equivariant means that if the input changes, the output changes in the same way. Specifically, a function f(x) is equivariant to a function g if f(g(x)) = g(f(x))
함수의 입력이 바뀌면, 출력도 바뀐다는 뜻으로, input의 위치가 바뀌면 output도 위치가 변한채로 나온다는 뜻이다.

Feature mapping 을 f , Translation을 g라고 하면 f(g(x))나 g(f(x))나 같다는 것을 보여주는 그림

parameter sharing을 통해 CNN은 equvariance 특성을 가질 수 있고, equvariance 로 인해 필터 하나로 하나의 이미지에서 다양한 특징들을 추출할 수 있게 된다.
4. translation invariant
pooling helps to make the representation approximatel invariant to small translations of the input. Invariance to translation means that if we translate the input by a small amount, the values of most of the pooled outputs do not change.
함수의 입력이 바뀌어도 출력은 그대로 유지되지 않는 다는 뜻이다.
이 성질은 그냥 Convolutional 에 의해 생기는 건 아니고 pooling 연산을 통해 생긴다.
아래 사진을 보면 pooling은 translation을 해도 값이 그대로 나온다. 이게 invariant 하다 라는 거 같다.
책에 보면 Max pooling introduces invariance라고 써있다.

내 생각에는 아래 그림이 equivariance와 invariance를 만족하는 것을 보여주는 그림인 거 같다.
사람의 위치가 변함에 따라, mapping 된 결과물의 위치도 달라진다. -> equivariance
하지만 결과물 그 자체가 빨간색 원으로 이뤄진 사람모양인 건 변함없다. -> invariance

Annotation data efficient learning
📌 Data Augmentation
- Dataset은 bias되어있음 ex) dataset을 보면 항상 날씨가 화창하다
- sample data는 real data의 극히 일부 -> 둘 사이의 gap을 메꿔줘야 함 -> data augmentation

- Modern Augmentation
- CutMix : 사진과 label 모두 합성 (label smoothing)
- RandAug : 여러 영상처리 기법 조합 ,영상처리들의 시퀀스를 policy라고 함.
적용할지, 어느 정도로 적용할지 라는 2개의 파라미터를 랜덤 샘플링 후 조합
👉 cv2 , torch transform 을 이용했는데 직접 구현해보는 것도 좋은 시도일 듯 하다.
📌 Leveraging pre-trained information
- Transfer learning
Approach 1 :Transfer knowledge from a pre-trained task to a new task
feature extract를 담당하는 CNN 부분은 freeze 시켜놓고 FC layer만 output_dim을 바꾼 후 , 파라미터를 훈련시킨다.
빠르고 데이터가 많이 필요하지 않지만 2번째 접근과 비교했을 때, 성능 변화는 덜 할 수 있다.

Approach 2 : Fine-tuning the whole model
FC layer를 바꾼 후, Convolutional layers는 낮게 FC 는 높게 learning rate를 설정해서 전체를 새로 업데이트한다.
1번 방법에 비해 느리고 데이터가 많이 필요하지만 성능 변화가 더 크게 일어난다.

💡 layer 별로 learning rate 조절하는 방법
처음 들어봐서 어떻게 하는 지가 너무 궁금해서 찾아봤다.
optimizer를 선언할 때, layer 별로 lr을 지정해주며 된다.
optimizer = torch.optim.Adam(
[{"params": nas_layers_params},
{"params": comm_layers_params, "lr": args.learning_rate/model.num_blocks_per_layer} # 公用层learning_rate应取平均
],
args.learning_rate)
- Knowledge distillation
이미 학습된 큰 모델을 '선생'으로 , 학습되지 않은 작은 모델에게 지식을 주입함
- 모델 압축(경량화)에서 사용
- unlabeld data의 pseudo-label을 만들어주기도 함

- soft label 사용 : one-hot과 다르게 quantization 되지 않음 , 실수로 표현
"지식"으로 간주 -> 더 많은 것을 표현할 수 있음
- softmax with temperature
softmax를 취했을 때, 값이 극단적으로 0과 1에 가까운 값으로 나뉘는 걸 방지하기 위해 Temperature로 나눠준다.
둘 사이의 극단적인 차이를 줄여주고, 입력에 따라 민감하게 바뀌게 만들어줌. 지식을 표현하는데 더 유용하다고 간주

- 2개의 loss의 weighted sum 사용 : Distillation Loss, Student Loss
Distillation Loss : 선생모델과 학생모델 사이의 분포가 비슷한 지 확인 , KLdiv를 이용해서 학생 네트워크가 선생 네트워크를 학습하고, 비슷해짐
Student Loss : 올바른 정답을 학습 , CE loss 사용
- Semantic Imformation 고려 x : Teacher의 output의 각각의 의미들 (ex. 차, 고양이) 들은 의미가 없다.
즉 선생 모델이 나타내는 추상적인 지식의 개형을 따라하게 만드는 것

👉 찾아보니 모델 경량화에도 많이 쓰이고 어떤 지식을 어떻게 전달하냐에 따른 차이도 존재한다고 한다. 이후에 논문을 찾아보면서 공부해볼만한 소재
📌 Leveraging unlabeled dataset for training
- Semi-supervised learning : Unsupervised + supervised
labeld dataset을 가지고 model을 학습
→ unlabeld dataset에 대해 model 이 predict
→ predict된 label을 pesudo-labeling 해줌
→ model을 다시 학습

📌 Self- Training
Augmentation + Teacher-Student Networks + Semi-supervised learning 사용
1. 적은 양의 labeld data를 이용하여 Teacher Model 학습
2. Teacher model이 predict한 label을 unlabeld data의 pseudo-label 로 사용
3. labeld data와 pseudo-labeled data에 RandAugment를 적용하여 Student Model 학습
이때 Teacher-student Network 사용 (이때 CEloss만 사용한다고 한다. )
4. train된 Student Model이 새로운 Teacher Model이 되어 1~3번 과정 반복
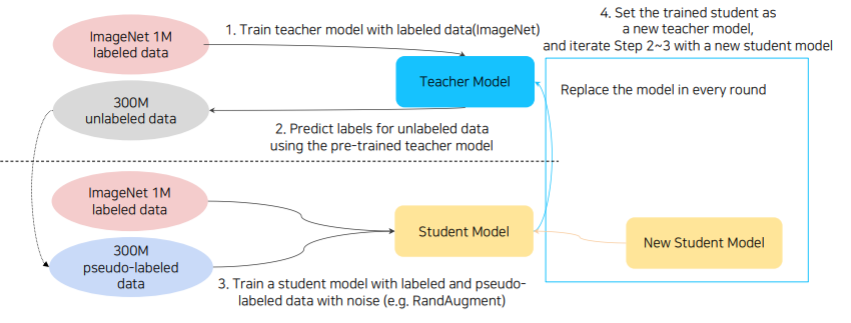
이 과정을 반복하면서 student model의 크기가 teacher model의 크기보다 커진다.
T = Teacher / S = Student
1) T & S = EfficientNet-B7
2) T = EfficientNet-B7 / S = EfficientNet-L0
3) T = EfficientNet-L0 / S = EfficientNet-L1
4) T = EfficientNet-L1 / S = EfficientNet-L2
5) T = EfficientNet-L2 / S = EfficientNet-L2
'Naver Ai Boostcamp' 카테고리의 다른 글
| [DAY 34] Instance/Panoptic segmentation & Conditional generative model (2) | 2021.03.17 |
|---|---|
| [DAY 33] Object Detection & CNN visualization (0) | 2021.03.17 |
| [Day 26] 특강 및 자율 공부 (0) | 2021.03.03 |
| [Day 25] GNN 기초 & GNN 심화 (0) | 2021.03.02 |
| [Day 24] 정점 표현 (0) | 2021.02.27 |