오늘 수업 내용은 이전 내용들과는 다른 의미로 너무 어렵다;;
최신동향이라 그런가,,, 완벽히 이해하겠다! 보다는 이런 컨셉으로 흘러가고있구나. 정도만 이해하는데 타협했다.
- DeepMind 소속의 Sebastian Ruder가 매년 블로그를 통해 발행하는 ML and NLP Research Highlights 의 2020년 버전 중 자연어 처리와 관련된 이야기만 번역한 포스트
- KAKAO BRAIN에서 발행한 2018-2020 NLP 연구동향

NLP에는 많은 분야가 있지만, 자연어 이해 NLU(Natural Language Understanding) , 자연어 생성 NLG(Natural Language Generation)를 핵심과제로 꼽아볼 수 있다고 한다.
생각해보면 주변에 CV를 하는 사람 혹은 관심있어하는 사람은 많아도, NLP를 하는 사람은 다소 드물다.
물론 요새는 많아지는 추세같긴 한데, 나만해도 이미지처리를 더 쉬워하는 경향이 있다.
그도 그럴 것이 CV는 IMAGENET과 같이 라벨링 되어있는 대량의 데이터가 있지만, 자연어처리에서는 라벨링 데이터를 확보하는 일 자체가 쉽지않다. 많은 양의 데이터도 얻지 못할 뿐 더러, 사전학습 시키는데 유용한 라벨링 방식조차 논의되지 못한 상황이었다고 한다.
항상 고난과 시련은 새로운 기회를 가져다준다.
1)비라벨링 데이터만 주어진 상태에서 입력 데이터 일부를 라벨로 사용하거나 사전 지식에 따라 라벨을 만들어 모델을 훈련하는 자기지도학습(self-supervised learning) 방법론이 발전
2)텍스트 훈련에 효과적인 딥러닝 모델 아키텍처가 개발
3)GPU와 딥러닝 라이브러리가 발전
위 3가지 덕분에 많은 양의 비라벨링 텍스트 데이터를 효과적으로 사전 훈련하는 모델 개발이 가능해졌다.
2017년 transfomer가 등장했다.
2018년 transformer를 여러 개 쌓은 구조의 self-supervised pre-training model인 ELMO, GPT1,BERT들이 등장하며 언어모델은 폭발적으로 성장하게 된다.
이전 모델들은 특정 task에 한정됐었지만, bert, GPT등의 모델들은 unsupervised 학습방식을 통해 텍스트 자체를 학습하고, 이후 transfer learaning을 통해 다양한 task를 수행하게 된다.
이후 후속작으로 더 많은 레이어를 쌓거나, 경량화 시킨 ALBERT , ELECTRA, DISTILBERT들이 등장했다.
최근 GPT3가 등장해 사람을 능가하면서 model size 만능론이 등장해 개인연구자 같은 소상공인들의 눈물을 훔치게했다.
GPT3의 등장으로 대기업이 아니면 어떡하냐, 점점 resource가 많은 대기업 중심으로 변해가고 있다, gpt3를 실제 산업분야에 어떻게 쓸 수 있을까?와 같은 얘기들도 많이 생기며 최근 clubhouse에서는 gpt3에 대해 얘기해보는 모임도 있었다.
사용하진 못하더라도 최대한 컨셉을 이해해보자.
📌 self-supervised-learning
딥러닝을 위해서는 대량의 레이블링된 데이터가 필요한데, 현실에서는 잘 labeling 된 데이터를 확보하는 것이 쉽지않다.
이를 위해 시간과 비용이 엄청나게 많이 들어가고, 실제로도 label알바도 있다.
"self supervised learning"은 현실에서의 위와 같은 문제점을 해결하기 위해 대두된 방안 중 하나이다.
supervision이란 지도,감독이란 뜻으로 우리가 흔히 아는 label을 의미한다고 생각하면 좋다.
self supervision은 자기 자신이 label 이 되어준다.
이미지의 경우, 어떤 feature를 추출하는 모델이 있다고 할 때, input 데이터의 한 부분이 다른 부분의 label이 되어주는 것이다.

라벨링이 되지 않은 데이터셋을 input으로 받아 사용자가 정의한 문제 (pretext task)를 학습해 데이터 자체에 대한 이해도를 높힌다. input을 가장 효과적으로 representation할 수 있다고 가정하는 것이다.
pretext task를 통해 pre-training 된 네트워크를 이미지라면 분류, nlp라면 기계독해와 같은 우리가 궁극적으로 풀고자 하는 문제(downstream task) 에 맨 마지막 output layer만 수정한다든지, transfer learning을 시켜준다.

이외 contrastive learning 방법론도 있는데 여기에 대해선 시간이 날 때 좀 더 자세하게 공부를 해봐야겠다.
- 고려대학교 연구실에서 진행된 발표를 참고함 .
- 여러 분야와 관련해 self-supervised learning 관련 paper list
📌 GPT 1,2,3
GPT1이 BERT보다 먼저 나왔는데 BERT가 더 큰 주목을 받은 거 같다.
trasformer decoder만을 12개 쌓아 language model을 구성한다.
Byte pair encodeing을 사용하여 문장을 토큰화 해주고, context-level embedding을 하는 과정을 통해 모델이 학습된다.
여기까지가 unsupervised 로 학습되는 부분이다.
이후 task에 따라서 transformer에 input을 다르게 넣어줘야한다.
논문을 읽는다든지, pytorch구현?을 본다든지 사실 그냥 NLP에 대한 공부가 좀 더 필요할 거 같다.

GPT2에서는 모델의 크기를 더 늘리고 ZERO-SHOT을 사용
GPT3에서는 모델의 크기와 파라미터를 어마어마하게 늘림 , FEW-SHOT 사용

📌 fewshot ❓❗
nlp 최신 동향과는 다소 거리가 먼 개념이긴 하지만 gpt3에서 사용됐다고도 하고, 요즘 핫하다고 하니 이런 거에 빠질 수 없는 나는 간단하게 써칭해보았다. kakao brain blog에 정리가 잘되어있다.
딥러닝에서는 데이터 양에 비례해 성능이 향상되는 경향이 있다. 아무리 좋은 모델이더라도 데이터가 적으면 그 성능을 십분 보여주지 못한다. 인간은 한 두번 본 사람도 잘 기억을 한다. 그에 비하면 모델은 소위 가성비가 후지다.
그래서 소량의 데이터(few shot)만으로도 좋은 학습 능력을 갖추는 것에 대한 연구가 바로 "few shot learing"이다.
few shot문제에서는 support data와 query data가 필요하다.
쿼리 하나에 필요한 support의 데이터의 개수가 k개면 k-shot이라고 한다.
당연히 k가 많을수록 성능이 좋아지겠지만, few shot은 적은 데이터를 가지고 하는 학습방식이다.

이때 새롭게 주어진 데이터에도 잘 작동하도록 만들기 위해서는 meta learning이 필요하다. meta learning은 few shot task와 유사한 형태의 훈련 task를 통해 모델 스스로 학습 규칙을 도출할 수 있게 해 일반화 성능을 높혀준다.
거리 학습 기반의 방식과 그래프신경망 학습 기반의 방식이 존재하는데 GNN에 대해서는 잘 모르니 PASS
다음주에 배울거다.
거리학습 기반 중에서도 가장 기본적인 방식은 서포트 데이터와 쿼리 데이터간의 거리를 측정하는 방식을 활용한다.
support data를 feature space에 표현하고 query data의 범주는 유클리드 거리 방식으로 거리를 측정해 가장 가까운 support data의 범주 내에 있다고 판단하게 됩니다. 두 데이터의 범주가 같으면 거리를 더 가깝게, 다를 땐 더 멀게 학습한다.

📌 Bert
지금은 NLP에 대해 1도 모르는 수준이지만, 정말 0도 모르는 수준일 때부터 BERT를 좋아했다.이유는 단지 가장 유명한데, 멋있어서...? 도균이가 맨날 BERT가 엄청나다해서....? 그래서 포스코에서 BERT 발표도 맡았었다. 근데 지금 다시 강의를 들어보니까 대체 어떻게 한 건지 모르겠다.
고등학교 영어 시험에서 제일 어려운 문제 유형을 뽑으라하면 10명 중 9명은 "빈칸 문제"를 얘기한다.
빈칸 문제는 앞뒤 문맥을 고려해, 빈 칸을 채우는 문제로 실제로도 전화를 하다 중간을 듣지 못하면 앞뒤 문맥을 고려해 맞추기도 한다. BERT는 이런 발상에서 고안되었다.
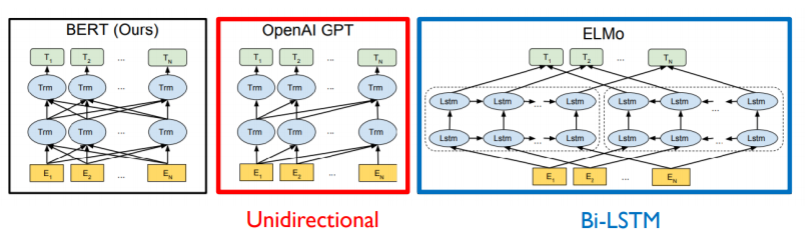
GPT1은 순방향으로만 바라보면서 그 다음에 나올 단어를 예측한다.
하지만 BERT는 순,역방향을 모두 고려해 masked language modeling task를 진행한다. 그렇기 때문에 "bi-directional"하다고 표현한다.
-
pretraining task
bert는 크게 2step으로 이뤄진다.
거대한 encoder가 입력문장들을 임베딩하여 language modeling을 한 후, fine-tunning을 통해 여러가지 자연어 처리 task를 수행한다.
"Masked Language Model" , "next sentence prediction" 2가지 pre-training task를 진행한다.
1. Masked Language Model
개인적인 생각이지만 bert의 핵심 구조?인 거 같다.

매번 서로 다르게 각 문장을 구성하는 단어 중 15%를 mask 토큰으로 변경해준다. model은 앞뒤 문맥을 고려해 mask에 무엇이 들어갈 지 예측하고 학습하게 된다. 이런 식으로 단어 시퀀스의 복잡한 관계를 잘 표현할 수 있게 된다.
15%보다 더 많이 해주게 되면 문맥을 학습하는데 충분한 정보가 제공되지 않아서 안되고, 15%보다 더 적으면 train을 하는데 오래 걸리거나 비효율적이다.
신기한 점은 15%의 확률 모두 mask 처리 해주지 않는다.
그렇게 되면 이 모델은 무조건 15%의 확률로 mask되는 패턴 자체를 학습해버리게 된다.
우리가 실제로 QA같은 task에서는 마스크 된 토큰이 없기 때문에 test와 train data의 양상이 달라져버려 모델의 학습력이 저하되기 때문이다.
- 80%는 [ MASK ] 토큰으로 대체
- 10%는 랜덤으로 다른 단어로 대체
- 10%는 원래 단어로 대체
15%중 10%를 랜덤으로 추출한 아무 단어로 대체하는데 이는 학습을 좀 더 어렵게 만들어 더 잘 훈련할 수 있도록 도와주는 역할을 한다.
2. next sentence prediction
두 문장이 서로 이어져있는지를 확인해준다. 문장a와 문장b가 같이 주어졌을 때, 문장a 다음에 문장 b가 나올만한 지, 아님 서로 연관이 없는 랜덤한 문장인지를 학습한다.

학습을 할 때는 실제로 연속되는 문장쌍과 랜덤으로 추출된 문장쌍을 1:1로 구성된다.
학습을 통해 문맥과 문장들의 순서를 언어모델이 학습할 수 있게 된다.
하지만 이후에 NSP는 큰 효과가 없다는 것을 연구한 논문들이 나오게 되빈다 ㅎㅎ,,,
-
input representation

3가지의 임베딩의 합으로 입력임베딩이 구성된다.
- Token embeddings : 토큰화된 단어에 대한 임베딩이다.cls는 문장의 시작을 의미하면서도 최종에 문장들에 대한 압축된 정보가 여기담긴다. wordpiece embedding을 사용했다.
- segment embeddings : NSP에서 두 개의 문장을 비교하는데 , 이때 사용된다. 각자 0,1로 앞의 문장인지 뒤의 문장인지 알려준다.
- position embeddings : transformer를 사용하기 때문에 위치 정보를 고려하기 위해 사용한다.
-
Transfer learning

(A) Sentence Pair Classification Tasks : MNLI , QQP , QNLI , STS-B , MRPC , RTE, SWAG
두 문장의 논리적 내포나 모순 관계를 판단하는 TASK이다.
두 문장이 SEP 토큰으로 연결되어 모델을 통해 CLS를 최종 OUTPUT으로 배출한다.
CLS는 한 번 더 classficaion layer를 거쳐 0,1로 표현돼 둘 사이의 관계를 분류한다.
- MNLI : 두 문장 사이의 내포 관계를 확인
- QQP : Qoura에 올라온 질문쌍이 의미가 유사한지 확인
- QNLI : SQuAD의 이진분류
- STS-B : 문장쌍이 얼마나 유사한지 확인
- MPRC : 문장쌍의 유사성 확인
- RTE : MNIL와 비슷하지만 데이터의 수가 적다.
- SWAG : 어떤 이미지 captioning 문제가 주어졌을 때, 이 뒤에 올 문장으로 4개의 문장 중 가장 자연스러운 것을 고르는 task

(B) single sentence classfication tasks : SST-2, CoLA
위와 마찬가지로 CLS를 OUTPUT으로 classficaion layer를 거쳐 0,1로 표현돼 분류한다.
- STT-2 : 하나의 문장에 대한 감정분석 (이진분류) 데이터셋
- CoLA : 영어 문장이 자연스러운지 확인하는 데이터 셋
(C) Question Answering Tasks : SQuAD v1.1
말 그대로 질의응답을 한다.
question과 지문이 주어지면 이를 두 문장으로 연결해 정답이 되는 문구?를 찾는다.
정답이 되는 문구의 시작과 끝을 알리는 start, end span이 추가된다.
- 스탠포드 대학에서 크라우드 소싱을 통해 만든 질의응답 데이터셋으로 SQuAD2.0까지 업그레이드됨
(D) single sentence Tagging Tasks : CoNLL-2003 NER
개체명인식등에 사용되는 단일문장에서의 각 토큰들이 어떤 CLASS를 갖는지를 분류한다.
- GLUE 벤치마크 결과
GLUE((Ganeral Language Understanding Evaluation))는 자연어 처리 모델을 훈련시키고, 그 성능을 평가 및 비교 분석하기 위한 데이터셋들로 구성되어있다. 다양하고 해결하기 어려운 9개의 NLU 태스크 데이터셋으로 구성된 GLUE는 모델들의 자연어 이해 능력을 평가하기 위해 고안되었다.
9개의 task에는 MNLI , QQP, QNLI , SST-2, CoLA, STS-B, MRPC, RTE, WNLI 가 존재한다.

BERT를 평가할 때는 WNLI는 빠졌다. 이전 ELMO, GPT와 비교했을 때, 훨씬 좋은 성능을 보여준다.
- BERT vs GPT-1
| BERT | GPT-1 | |
| data-size | 800M 단어 | 2500M 단어 |
| special token | SEP, CLS 토큰과 segment embedding 사용 | |
| batch size | 128000 | 32000 |
| learning rate | 모든 fine-tunning 실험에 대해 5e-5 | task-specific하게 lr 적용 |
| layer | base : 12 , large : 24 | 12 |
📌 ALBERT
- 기존 BERT의 학습 시간이 오래 걸리고, memory가 크다는 점을 보완하면서도 더 높은 성능을 보이기도 했다.
- Factorized Embedding Parameterization
: 상대적으로 덜 중요한 embedding을 압축시켰다. VxE사이즈의 embedding matrix에 W를 곱해주어 ExH일 때와 근사하게 만들어준다. 이렇게 되면 parameter수를 압도적으로 줄일 수 있다.

- cross layer parameter sharing
: 기존 bert에서는 FFN, attention에서 서로 가중치를 공유하지 않고, layer마다 가중치를 따로 사용했다.
albert에서 공유할 때, 공유하지 않을 때 등 비교를 해보았을 때, 성능의 큰 차이는 없지만 parameter의 수가 확 줄어든다. 오히려 attention을 공유했을 때가 더 높은 것을 보여주기도 한다

- sentence order prediction
: 기존 bert 에서의 NSP는 너무 쉬워 큰 의미가 없다는 논문이 많이 나왔었다. 그래서 이를 대체하는 SOP로 대체
SOP란 두 문장 사이의 순서를 고려하는 거다. 자연스럽게 두 문장이 서로의 순서에 맞게 나왔는지 확인하는 TASK다. NSP를 사용했을 때보다 성능이 좋다.

📌 ELECTRABERT
GAN에서 영감을 받아 모델을 학습해 실제와 가짜를 구별한다.
BERT의 MLM처럼 MASK를 generator를 통해 그럴듯한 토큰으로 대체해준다.
그 후 discriminator를 통해 가짜인지 실제인지 구별해준다.
실제 electra의 핵심은 discriminator다. discriminator는 downstream task에서 fine-tunning된다.
성능은 어마어마하다. 특정 GLUE score에 도달하기까지 다른 모델들에 비해 소요되는 step이 확실히 적다.

brunch.co.kr/@synabreu/55 를 참고했다.
이런 큰 모델들을 상용화하기 위해 시간과 자원을 줄이는 DistilBERT , TinyBERT, MobileBERT 등의 경량화 모델도 최근 많이 나오고 있다.
KAKAO brain에 따르면 위의 모델들이 실제로 자연어를 이해했다고 보기는 어렵다고 한다. 실험데이터에 존재하는 bias , artifact 등을 익혀 현실문제를 제대로 풀지 못하는 맹점이 있다고 한다. 그렇기 때문에 외부 지식을 모델에 내재화하거나 따로 저장한 외부 지식을 활용하는 학습 메커니즘이 주목받고 있다. 최근 관계 기반 질의응답 과제에서 별도의 지식 그래프 (knowledge graph)를 이용해 사실관계를 표현하는 연구와 모델들이 활발히 나오고 있다고 한다. ENRINE , KagNET 와 같이 추론적 지식 그래프와 언어모델을 조합해 추론 능력을 높힌다고 한다.
어쩌다 글을 쓰다 보니 bert 중심으로 쓰게 되었다.
사실 위의 모델들을 전부 완벽히 이해하지는 못했다. 이 부분은 논문을 직접 읽어보고 구현코드를 봐야 할 거 같다.
하지만 중요한 건 현재 NLP분야의 큰 흐름이 "self -supervised pre-train model"을 사용한다는거다.
GPT1 - BERT(다시) - ALBERT - ELECTRABERT - GPT3 정도는 읽어보자.
피어세션
같이 과제를 했다. 캐글 시스템이라든지 ipynb에서 config에 저장된 모델을 py로 훈련시키는 방법들이 익숙치 않아 조원들과 함께 "집단지성"을 보여줬다. 잘 모르는 부분은 그냥 모르는 다른 조 캠퍼한테 물어봤다. 왜냐? 다른 조인게 중요한 게 아니고 같은 목표를 가지고 노력하는 "캠퍼"라는 게 중요하다^^ 그냥 합리화다. NER task에 대해서는 뭔지 알겠는데 이걸 어떻게 tunning 할 건지 감이 안잡힌다.
일주일 소감
벌써 또 1주가 지났다. 시간이 너무 빠르다.
NLP를 고작 5일 배운 거로는 NLP를 마스터하기에는 너무 부족하다 ;;
vision과는 다르게 감도 안잡힌다....
주말동안 못 따라간 실습 내용도 좀 이해하고, mask rcnn논문도 읽어야되고, 선형대수학 살짝 밀린 거 복습도 해야되고 할 게 많다. 다 할 수 있을까? 과연! 월요일을 기대하시라 두둥탁!
'Naver Ai Boostcamp' 카테고리의 다른 글
| [Day 22] 페이지랭크 & 전파 모델 (0) | 2021.02.23 |
|---|---|
| [Day 21] 그래프 이론 기초 & 그래프 패턴 (0) | 2021.02.22 |
| [DAY 19] Transformer (0) | 2021.02.18 |
| [DAY 18] Seq2seq , beam search , BLEU (1) | 2021.02.17 |
| [DAY 17] RNN & LSTM & GRU (0) | 2021.02.17 |