sequ2seq with attention📌 seq2seq
한국사람이라면 한 번쯤은 papago를 사용해봤을 겁니다. 저도 영어논문을 읽다 이해가 안되면 파파고를 돌려봅니다 ㅎ
기계번역 (Machine Translation)이란 task는 source language(영어)에서 target language(한국어)로 번역해주는 task를 얘기합니다. 1950년대 초반부터 기계번역이 시작되었고, 2010년도까지는 통계적인 방식에 의존해 번역을 진행했습니다.
2014년도 NMT (Neural Machine Translation)가 neural network를 이용하여 기계번역을 하며 엄청난 변화를 가져왔다고 합니다. 얼마나 대단하면 cs224n강좌 ppt에 이런 그림이 있을까요 ㅋㅋ;
그리고 NMT를 가능하게 해준 핵심 neural network architecture가 바로 seq2seq입니다.

seq2seq는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 모델로, 챗봇(질문-대답) , 기계번역(한국어-영어), 심지어 코딩에서도 사용됩니다.
seq2seq는 각각 encoder , decoder로 불리는 2개의 rnn으로 구성되어있으며, sequence(문장)을 입력으로 받고, 입력이 끝나면 sequence를 출력합니다.
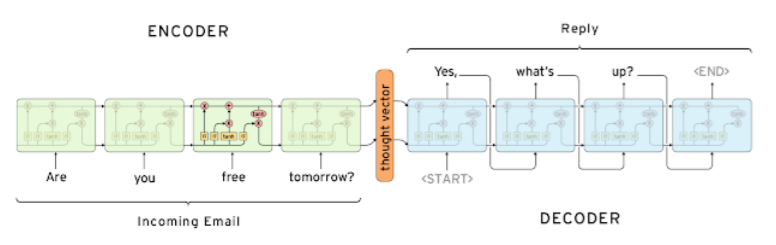
입력문장을 받는 RNN을 ENCODER라 하고 생성 혹은 예측된 문장을 출력하는 RNN을 DECODER라고 합니다.
실제 성능 문제로도 그렇고 위의 그림도 그렇고 Vanilla RNN보다는 LSTM , GRU로 구성합니다.
인코더는 모든 입력문장을 input으로 받은 후, 인코더에서의 맨 마지막 step의 hidden state 즉, 이 입력문장들이 잘 압축 또는 요약된 정보들을 decoder에 넘겨줍니다. 이 hidden state를 context vector라고도 부릅니다.
decoder에서는 context vector를 받아 첫번째 hidden state로 사용됩니다.
encoder에서는 첫번째 hidden state를 0으로 초기화해 사용했겠지만 ,decoder에서는 encoder로부터 받은 context vector를 첫번째 hidden state로 사용하게 됩니다.
decoder에서는 시작을 알리는 <SOS> token을 맨 처음 input으로 받게 됩니다.
그 후 softmax를 거쳐 다음에 등장할 확률이 가장 높은 단어를 출력하고, 출력된 단어는 다음 timestep의 input이 됩니다.
그림에서 보면 1번째 timestep에서 start token이 input으로 들어가 yes를 출력하고, 이 yes가 2번째 timestep의 input이 됩니다. 이런 식으로 문장의 끝을 알리는 <EOS> token이 출력될 때까지 반복됩니다.
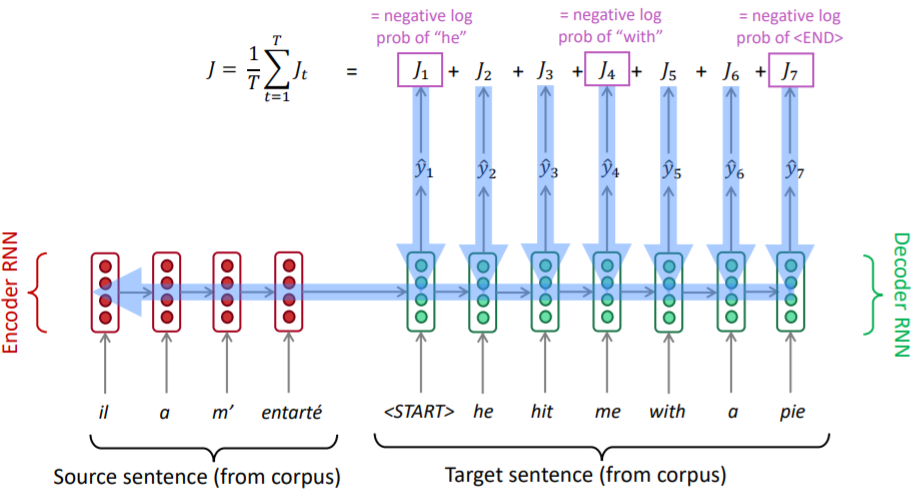
문장 $X$와 이전 단어 $y_{t-1}$이 주어졌을 때, y_{t}가 나올 확률을 최대로 하는 모델 파라미터 (W)를 MLE를 통해 학습하게 됩니다.
$\theta^* \approx argmaxP(Y|X;\theta)~where~X=\{x_1,x_2,\cdots,x_n\},~Y=\{y_1,y_2,\cdots,y_m\}$
여기서 잠깐!
train 초기에는 학습이 덜 됐기 때문에 다음에 올 단어로 이상한 단어를 출력하게 될 테고, 그러면 전체 문장에도, train에도 영향을 주게 됩니다. train 시에 우리는 ground truth 즉 정답을 알고있습니다! 그렇기 때문에 train 시에는 출력된 문장이 틀렸더라도, ground truth를 다음 스텝의 input으로 넣어주어 올바르게 학습할 수 있도록 도와줄 수 있습니다.
이게 바로 "teacher forcing" 입니다. "yes"를 input으로 넣어 "up"으로 잘못 출력했더라도, 그 다음 step에는 ground truth인 "what's"를 input으로 넣어주는 겁니다.
예를 들면 학교에서 사칙연산을 막 처음 배울 때는 마구 틀릴테니까, 선생님이 옆에서 보면서 지도해주는 겁니다.
한 문제를 풀고 틀리면 제대로 된 답을 바로 알려주어 학습하고, 그 다음 문제를 또 푸는 걸 반복하는 겁니다.
train시에는 teacher forcing이 가능하지만 test시에는 ground truth를 모르므로 불가능합니다! 특정 epoch까지는 teacher forcing을 사용하고 어느정도 훈련이 됐다면 사용하지 않는 방법도 있습니다.
하지만 seq2seq에도 문제점이 있습니다.
우선 하나의 고정된 크기의 벡터 (인코더에서의 마지막 스텝의 hidden state 또는 context vector)에 입력문장의 정보를 요약하려고하다보니 정보가 많이 유실됩니다. bottleneck problem이기도 합니다.
"시작이 반이다"라는 말 처럼 decoder에서는 이전 step의 output이 다음 step의 input이 되므로 어떻게 시작하냐에 따라서 문장이 decoder가 생성하는 문장이 바뀝니다. 보통 주어가 맨 앞에 존재하는데, 주어까지의 길이가 너무 길어 정보가 유실된다면 decoder에서는 맨 처음부터 잘못된 output을 출력하게 됩니다.
그래서 I go home을 번역하고 싶다면 home go I 이렇게 거꾸로 입력을 넣어주는 꼼수도 존재합니다.
그래서 feature vector가 20이하일때만 잘 된다고 합니다.
또한 위 그림처럼 seq2se1는 end-to-end로 학습됩니다.
encoder에서부터 하나하나 순차적으로 진행되기때문에 backpropagation이 진행될 때도, encoder의 1번째 step까지 가려면 엄청나게 먼 길을 걸어와야합니다. 그러다보면 결국 vanishing gradient문제가 존재하게 됩니다.
LSTM이나 GRU를 사용하여 일부 해결할 수는 있지만 , 입력시퀀스가 길어지면 정확도가 떨어지게 됩니다.
📌Seq2seq with attention
이 논문에서 attention을 이용하여 seq2seq의 문제점들을 보완했습니다. (논문에서는 alignment로 표현)
attention의 기본 아이디어는 encoder에서의 각 timestep에서의 hidden state를 decoder가 다음 단어를 예측할 때 참고하는 것입니다. encoder에서 각 timeste마다 출력되는 hidden state를 concat해 따로 기억해준 후 seq2seq와 똑같이 context vector를 decoder에 넘겨줍니다.
그러면 decoder에서는 다음 단어를 예측할 때 context vector와 concat한 hidden state를 통해 집중해야되는 source sequence부분 이렇게 2가지를 이용하게 됩니다.

encoder에서의 각 step별 출력된 hidden state를 $h_{1}^{e}, h_{2}^{e}, h_{3}^{e}, h_{4}^{e}$ 라고 해봅시다.
그러면 마지막 step의 hidden state인 $h_{4}^{e}$는 decoder의 0번째 hidden state로 넘겨주게 됩니다.
decoder에서는 <start> 토큰을 input으로 입력받아 다음에 올 단어인 output을 예측할 때 두 가지 정보를 사용합니다.
일단 decoder에서는 $h_{0}^{d}$와 $x_{1}$을 input으로 받아 $h_{1}^{d}$를 만듭니다.
첫번째로는 decoder 내에서의 hidden state로 <start>token 기준으로는 $h_{1}^{d}$가 됩니다.
두번째로는 attention output을 사용하게 됩니다. 지금 당장 다음 단어를 예측하기 위해 source sentence의 어떤 단어를 참고해야되는지 선별하는 과정입니다.
$h_{1}^{d}$가 encoder의 hidden state인 $h_{1}^{e},h_{2}^{e},h_{3}^{e},h_{4}^{e}$과 각각 내적을 해 하나의 스칼라값을 구합니다. 이 내적값은 일종의 유사도로 간주합니다. 즉 내적값이 크면 둘이 유사하다고 판단하게 됩니다.
이후 이들을 하나의 확률분포로 나타내기위해 softmax를 취해 줍니다.
예를 들어 attention score에 softmax를 취한 벡터가 [0.85 , 0.08 , 0.04 , 0.03]이라고 나왔다면 각각을 $h^{e}$와 곱해주어 가중합을 구해줍니다. $ 0.85h_{1}^{e} + 0.08 h_{2}^{e} +0.04 h_{3}^{e} + 0.04h_{1}^{e}$를 element wise 하게 더해줍니다. 이걸 attention output이라고 하는데 attention score가 높을수록 예측할 단어와 높은 유사도를 가지게 됩니다

attention output과 decoder에서의 hidden state $h_{1}^{d}$이 concat된 후 기존 seq2seq와 동일하게 linear + softmax를 거쳐 그 다음 나올 단어를 에측하게 됩니다.
수식을 통해 한 번 더 정리하면
1. encoder 각 step별 hidden state $h_{1} , h_{2} , \cdots , h_{N} \in \mathbb{R}^{h}$ 를 따로 저장
2. timestep t에서 decoder의 hidden state $s_{t} \in \mathbb{R}^{h}$
3. 이 둘의 내적을 통해 attention scroes $e^{t}$를 구한다. $e^{t} = [s_{t}^{T}h_{1} , \cdots , s_{t}^{T}h_{N}]\in \mathbb{R}^{N}$
4. e^{t} 에 softmax를 취해 t step에 해당하는 attention distribution \alpha ^{t} 를 구한다
$\alpha ^{t} = softmax(e^{t})\in \mathbb{R}^{N}$
5. attention output $a_{t}$를 얻기위해 $\alpha ^{t}$와 encoder의 가중치들에 가중합을 취해준다. $a_{t} = \sum_{i=1} ^{N}\alpha _{i}^{t}h_{i} \in \mathbb{R}^{h}$
6. 마지막으로 $a_{t}$와 $s_{t}$를 concat한 결과물을 seq2seq와 동일하게 linear + softmax를 통해 다음에 나올 단어를 예측해줍니다.
attention을 사용했을 때의 장점들로는 여러가지가 있습니다.
1. 우선 기계번역의 성능이 엄청나게 좋아졌습니다. 감정분석같은 경우는 모든 문장의 정보가 압축되지 않아도 됩니다. I like it 이라는 문장이 있으면 "like"만 압축되어도 무관하고, I와 같은 단어는 손실해도 큰 상관이 없습니다. 하지만 기계번역 task의 경우 모든 문장이 손실없이 압축이 되어야하는데 attention을 통해서 손실이 줄어들어 성능이 좋아졌습니다.
2. bottleneck problem을 해결했습니다. 기존 seq2seq는 인코더의 마지막 스텝의 hidden state에만 의존했기 때문에 bottleneck문제가 있었습니다.하지만 attention을 사용해 decoder가 source sequence까지 직접적으로 고려할 수 있게 되면서 bottleneck문제를 해결할 수 있게 되었습니다.
3. vanishing gradient problem을 해결했습니다. 기존 seq2seq에서는 source sequence의 첫 단어의 가중치를 학습하기 위해서는 머나먼 길을 돌아가야했습니다....하지만 attention을 사용하면 $h_{1}, h_{2} , \cdots, h_{N}$ 를 하나의 matrix로 표현해 병렬처리가 가능합니다.병렬처리를 통해 첫 단어에 해당하는 가중치를 돌아서 가지 않고 바로 학습할 수 있게 됩니다. 일종의 지름길 같은거죠 그래서 먼 state에 한 번에 갈 수 있는 shortcut을 제공해줌으로써 vanishing gradient problem문제를 해결했습니다.
4. 해석가능성...?을 제공해줍니다. 그림으로 보는 게 빠릅니다.

위 그림은 attention matrix를 시각화한 heatmap입니다.
행을 source , 열을 target이라고 보고 색깔이 밝을수록 attention score가 높은 겁니다.
(a)는 "zone economique europeenne"는 "european economic areas"에 해당하는데 어순이 반대입니다.
그래서 다른 단어들과는 다르게 역대각선 방향으로 attention score가 높은 걸 볼 수 있습니다.
(c)에서는 la Syrie가 Syria로 표현되는 걸 볼 수가 있습니다.
평소 source와 target 길이가 다르면 어떻게 표현되나 싶었는데 호오 신기합니다.
📌 Attention 삼총사 : Query , Key , Value
Attention 메커니즘은 이후 발전해 여기저기 다양한 architecture와 task에서 사용되고 있습니다.
attention의 좀더 일반적인 정의에 대해 알아보면 cs224에서는 아래와 같이 정의했습니다.
Given a set of vector values, and a vector query, attention is a technique to compute a weighted sum of the values, dependent on the query.
value와 query가 주어졌을 때 query에 관해 values 들의 가중합을 계산하는 테크닉이라고 합니다
Query , Key , Value 에 관해서 먼저 알아야 하는데 이게 적절한 예일지 모르겠지만 이렇게 이해를 하면 편합니다.
- Query : 질문 ("I"와 누가 유사하니?)
- Key : 대답 ( "나")
- Value : 대답에 대한 점수("I" : "나"에 대해서 가중치 10 )
Attention은 주어진 query에 대해 모든 key와의 유사도를 각각 구합니다. 그리고 이 유사도를 vlaue에 반영해줍니다.
이걸 모두 더한 게 attention output이라고 하겠습니다.
<start> token을 의미하는 디코더의 hidden state가 attention의 Query입니다. 즉 encoder에게 물어보는겁니다.
누가 <SOS>뒤에 와야될까? 뭐가 유사도가 높을까?
일종의 질문에 대한 답인 Key가 query와 곱해집니다. 여기서의 Key는 모든 시점의 encoder의 hidden state들입니다.
각각 les, pouvres, sont, demunis를 의미하는 key인 hidden state들이 query와 곱해져 유사도를 계산하는 겁니다.
둘이 곱해져 attention score가 나오게 됩니다.
그럼 이제 답에 대한 점수인 Value가 attention score와 곱해집니다. 현재 seq2seq에서 value는 모든 시점의 encoder의 hidden state들입니다.
각각의 attention score와 value가 곱해지고 weighted sum을 통해 하나의 attention output을 만들어냅니다.
attention output은 query가 어떤 value에 집중할지에 대한 정보를 담고있는 selective summary입니다.
정리하자면
- Q : t 시점의 decoder에서의 hidden state
- K : 모든 시점에서의 encoder에서의 hidden state
- V : 모든 시점에서의 encoder에서의 hidden state
📌 다양한 Attention 기법들 (Loung , banadahu)
1. basic dot-product attention (Loung attention)
위에서 했던 가장 기본적인 dot product attention이며 Loung attention이라고도 불린다.
\begin{align}score(s_{t},\ h_{i}) = s^{T}_{t}h_{i}\end{align}
t step에서의 decoder의 hidden state와 모든 시점에서의 encoder에서의 hidden state를 내적해서 구한다.
softmax를 거친 후 모든 시점에서의 encoder에서의 hidden state와 곱해져 t step에서의 decoder의 hidden state와element-wise하게 더해진다.
더해진 값은 t시점의 decoder의 output을 예측하는데 사용된다.
2. general dot product
\begin{align}score(s_{t},\ h_{i}) = s^{T}_{t}W_{a}h_{i}\end{align}
1번의 기본 dot-production을 중간에 학습가능한 가중치 W를 추가해 확장한 형태입니다.
basic dot-product attention은 W가 항등행렬인 특수한 케이스라고 생각해볼 수 있습니다.
3. concat attention (Bahdanau attention)
Loung attention에 비해 좀 더 복잡한 attention 입니다. \begin{align}score(s_{t},\ h_{i}) = W_{a}^{T}\ tanh(W_{b}[s_{t};h_{i}]) \\ score(s_{t},\ h_{i}) = W_{a}^{T}\ tanh(W_{b}s_{t}+W_{c} h_{i})\end{align}
dot product와는 다르게 t-1 step에서의 decoder의 hidden state와 모든 시점에서의 encoder에서의 hidden state를 내적해줍니다. 이후 tanh를 한 번 거친 후 output과의 dimension을 맞춰주기 위헤 한 번더 W과 곱해줍주어 attention score를 구해줍니다. \begin{align}score(s_{t-1},\ H) = W_{a}^{T}\ tanh(W_{b}s_{t-1}+W_{c}H)\end{align}
softmax를 거친 후 모든 시점에서의 encoder에서의 hidden state와 곱해집니다.
이를 context vector라고 부르면 context vector는 t step의 input으로 들어오는 t-1 step의 output과 concat 되어 lstm 셀에 input으로 들어가게 됩니다. 이후 과정은 attetntion이 없는 seq2seq와 같습니다.
t시점의 input과 t-1시점의 hidden state를 이용하여 t시점의 hidden state를 만들어 냅니다.

Beam search
📌 Greedy decoding
seq2seq모델은 이전 단어와 x들에 의해 결정되는, 조건부 확률분포에 따라 다음 단어를 예측합니다.
즉 이전 timestep에서의 output이 다음 step의 input이 되고, 되돌릴 수 없기 때문에 아주 잘 신중히 고민해야됩니다.
단순하게 softmax를 취한 값 중 argmax의 index에 해당하는 단어를 다음 단어로 예측하는 방식을 "Greedy decoding"이라고 합니다. 근시안적으로 현재 step에서 가장 확률이 큰 단어를 선택하는 겁니다.

위 예시와 같이 hit 기준으로 a의 확률이 가장 커 출력했지만 , a가 잘못됐단 걸 꺠달아도 되돌릴 수 없습니다ㅜㅜ
이 방법은 너무 단순해서 문제가 됩니다. 그렇다면 디코더에서 출력된 모든 단어를 고려하는 건 어떨까요?

이 경우 전체 문맥을 고려하는 방법이기 때문에 제일 이상적이겠지만 연산의 수가 너무 많기 때문에 현실적으로 불가합니다.
1번째 단어를 예측할 때는 사전의 크기인 v만큼의 경우의 수를 생각하고, 2번재 단어를 예측할 때는 첫번째 단어가 나오는 모든 경우의 수에 대하여 또 모든 사전 내 단어를 고려해야되므로 $v^{2}$만큼 생각해야됩니다.
결국 t step의 단어를 예측하기 위해서는 $V^{T}$만큼 고려해야되므로 너무 오래 걸립니다.
📌 Beam Search
이 사이 절충방안으로 등장한 것이 바로 "Beam Search"입니다.
beam search는 가장 확률이 높은 k개의 경우의 수(hypotheses)만 고려하는 것입니다.
bfs방식으로 보면서 score가 가장 높은 경우 k개만 선택해서 가지를 뻗어나가는 것을 반복합니다.
주로 k는 5~10 사이를 사용한다고 합니다.
global하게 최적화된 해는 아니지만 그래도 위의 두가지 예시보다는 훨씬 효율적입니다.

Score는 첫번째 단어부터 t step의 단어까지 모두 고려해 계산하게 됩니다.
하지만 hypothesis의 score만 계산하기때문에 연산량을 줄일 수 있게 됩니다.
0~1 사이의 확률들을 계속 곱하다보면 이진수로 표현하는 컴퓨터가 0.0000000000001 같은 수를 그냥 0으로 바꿔버릴 수도 있습니다. 그래서 log를 취해서 곱이 아닌 덧셈으로 바꿔주어 계산하게 됩니다.
곱이 제일 크다면 어차피 합도 제일 크기 때문에 log를 취해도 가능합니다. score들은 모두 음수로 이루어져있는데 0~1사이 확률값에 log를 취하게 되면 음수가 나오기 때문입니다.

예를 들어 beam_size = 2라면 <start> 토큰을 input으로 했을 때 사전 내 단어들 중 가장 score가 높은 값 두 개만을 선택합니다. score를 구하는 수식은 아래에서 보겠습니다!
그 후 score가 높은 "he" 와 "i"가 input token인 경우를 생각해줍니다.
그러면 "he"가 input일 때 score가 가장 큰 2가지 경우의 수 , "i"가 input일 때 score가 가장 큰 2가지 경우의 수 총 4가지 경우의 수를 생각해볼 수 있습니다. 이때 4가지 중 "he hit"과 "i was"가 가장 score 가 높으니 이 2가지 hypotheses만 선택합니다.

"hit"가 input일 때 score가 가장 큰 2가지 경우의 수 , "was"가 input일 때 score가 가장 큰 2가지 경우의 수 총 4가지 경우의 수를 생각해볼 수 있습니다. 총 4가지의 경우 중 "he hit a" , "he struch me"가 가장 score가 크므로 이 2가지 hypotheses를 선택합니다. 또 다시 "a" , "me"가 input일 때 각각 2가지 경우씩을 생각해 총 4가지를 생각해볼 수 있고,
"he hit a pie" , "he hit me with"일 때 score가 가장 높으니 이 2가지 hypotheses를 선택합니다.
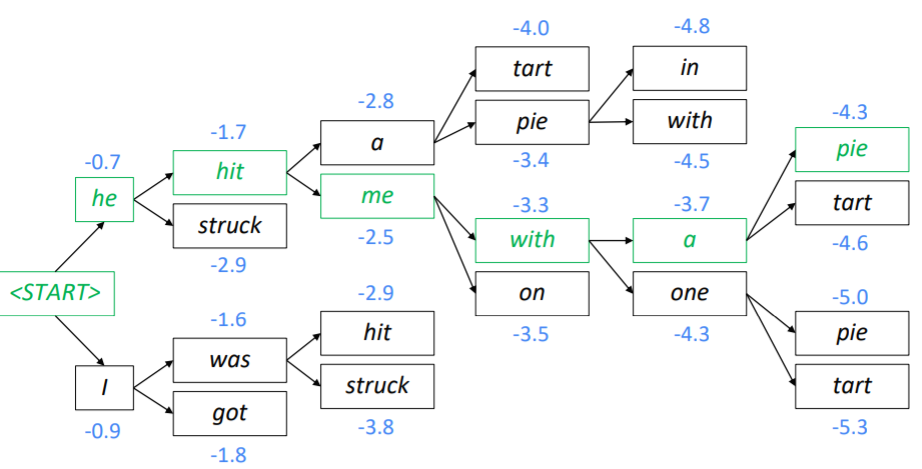
이런식으로 <end> token이 나올 때까지 반복하면 됩니다.
하지만 총 k가지의 hypotheses 에서 end token이 나오는 시점은 각각 다릅니다.
하나의 hypotheses기준으로 end token이 나오면 끝난거고, 이 결과는 임시로 저장을 해놓고 아직 끝나지 않은 hypotheses들은 진행을 합니다. 하지만 끝날 기미가 보이지 않으면 timestep T를 정해 이 T를 기점으로 이전에 끝난 문장들만 고려할 수 있습니다.
k=3인 경우
- "i want to go home"
- "i love math"
- "i studied machine learning that enables ... "
hypotheses가 주어졌을 때, T=5로 절정하게 되면 아직 끝나지 않은 3번째 문장에 대해서는 취급하지 않습니다.
그렇다면 "I love math"와 같이 짧은 문장과 "i want to go home"와 같이 긴 문장에 대해서는 필연적으로 "I love math"의 score가 더 높을 수 밖에 없습니다. 문장이 짧기 때문에 score가 더 높을 수 밖에 없기때문입니다.
그래서 문장의 길이로 score를 나눠주어 normalize 해줘 해결할 수 있습니다.

BLEU (BiLingual Evaluation Understudy)
모델이 얼마나 좋은 성능을 내는지 평가할 차례입니다.
단순히 같은 위치에 같은 단어가 있을 때, 점수를 매긴다면
"I love you"
"Oh I love you"
와 같은 두 문장은 매우 유사하지만 oh때문에 위치가 맞는 단어가 없어 0으로 평가하게 됩니다.
번역이 얼마나 잘 됐는지, 유사한 지를 측정하는 지표가 필요합니다.
BLEU는 기계번역의 성능을 측정하는 대표적인 지표 중 하나입니다.
n-gram에 기반해 기계 번역 결과(predicted)와 ground-truth가 얼마나 유사한 지 비교합니다.
BLEU에 대해 알기 전에 precision, recall이 무엇인지, n-gram이 무엇인지 알아야 합니다.
📌 confusion matrix
자세한 설명은 여기 숨겨놨다.

confusion matrix는 분류를 위한 지표인데 언어모델에 사용한다고 생각해보면
TP + FN 이 ground truth에 해당하는 sequence
TP + FP 는 모델이 prdeict 한 sequence
TP는 ground trurh에도 존재하면서 prediction에도 존재하는 잘 예측한 word
라고 생각해본다면
모델이 예측한 문장 중 모델이 예측한 word와 ground trurh가 맞는 word은 TP / TP+FP로 prediction을 의미하게 된다.

ground truth 중 모델이 예측한 word와 ground trurh가 맞는 word는 TP / TP+FN로 recall을 의미하게 된다.

precision과 recall을 이용해서 아래와 같이 문장의 유사도를 측정할 수 있다.

그러면 평가지표로 precision , recall을 사용하면 안될까? 안된다.
아래와 같이 단어는 동일하지만 순서가 뒤죽박죽인 말도 안되는 sequence가 출력됐다고 할 때, 단어 자체는 전부 맞기 때문에 100%가 나오게 된다. 즉 reorder에 penalty가 부가되지 않기 때문에 문제가 된다.
📌n-gram
n-gram은 n개의 연속적인 단어 나열을 얘기합니다.
n-gram은 오로지 앞의 n-1개의 단어에만 의존해 n개의 단어가 ground truth와 맞다면 correct하다고 판단합니다.

위와 같은 reference , predicted 예제에 대해 gram을 구해보면
n= 1 즉 unigram일 때는 단어 하나가 맞는지를 바라봐 총 9개 중 7개가 맞게 됩니다.
n =2 bigram일 때는 연속한 단어 두개가 맞는지를 확인합니다.
"my heart" , 'heart is ", "is in","ooh na"총 4개가 일치하므로 8개의 연속한 두 단어 중 4개가 맞게 됩니다.
n = 3 trigram일 때는 "my heart is" , "heart is in" 2개가 일치하므로 7개의 연속한 세 단어 중 2개가 맞게 됩니다.
📌 BLEU
1~4까지의 n-grams에 대해 precision을 계산한 값을 사용하게 됩니다.
n-gram recall이 아닌 precision을 쓰는 이유는 "얼마나 빠짐없이 번역했느냐" 보다 " 모델이 얼마나 맞추었는가"에 집중하기 위함입니다.
예를 들어 I love this movie very much -> 나는 이 영화를 많이 사랑한다. 라고 번역했을 경우 "너무"가 번역되지 않았지만 의미는 99.99% 비슷하다.이 경우 recall 관점으로 계산하게 되면 5/6가 되지만 precision의 관점에서 보면 1이 된다.

brevity penalty와 n-gram overlap 두 항으로 구성됩니다
brevity penalty는 너무 짧게 생성된 번역에 페널티를 적용해주는 역할을 합니다.
예를 들어 아래와 같이 문장이 주어지면
- Predicted : it is
- Reference : It is a guide to action that ensures that the military will forever heed Party commands.
이 문장은 엉터리로 번역이 되었지만 1-gram , 2-gram precision이 모두 1로 높은 정밀도를 얻습니다.
이와 같이 제대로 된 번역이 아니지만 일부 짧기 때문에 높은 score를 받으면 안되므로 brevity penalty를 주게 됩니다.
그리고 BLEU가 recall을 사용하지 않는 점을 보완해줍니다.
❗ 편의상 문장이라고 표현하고 있지만 BLEU는 문장이 아닌 하나의 하나의 corpus에 대해 진행됩니다.
n-gram overlap은 n-gram precision을 통해 얼마나 일치하는지를 측정해줍니다.
1~4gram들의 "기하평균"을 사용합니다
예를 들어
-
Predicted : the the the the the the the
-
Reference1 : the cat is on the mat
인 경우 unigram precision은 7/7=1이 됩니다.
같은 단어만 여러번 반복하기 때문에 "중복"에 대한 문제가 생기는데 이를 보정하기 위해 predicted의 n-gram이 reference문장의 n-gram과 매칭된 적 이 있는지의 여부를 고려하게 됩니다.
n=1로 고정한 후 설명하겠습니다.
유니그램이 reference 문장 내 최대 몇 번 등장했는지 카운트합니다. 이 값을 max_ref_cnt라고 부르겠습니다.
max_ref_cnt가 기존의 카운트값보다 작은 경우 이 값을 최종 카운트 값으로 개체합니다. \begin{align}Count_{clip}\ =\ min(Count,\ Max Ref Cnt)\end{align}
이를 통해 unigram precision을 다시 계산하면 \begin{align}\text{Modified Unigram Precision} =\frac{\sum_{unigram∈Candidate}\ Count_{clip}(unigram)}
{\sum_{unigram∈Candidate}\ Count(unigram)}\end{align}
위의 예시를 다시 계산해보면 reference에서 the라는 문장은 2번 나왔기 때문에 max_ref_cnt = 2 이 됩니다.
다시 계산하면 unigram precision은 2/7이 됩니다.

Further Question : BLEU score가 번역 문장 평가에 있어서 갖는 단점은 무엇이 있을까요?
Google automl docs 를 참고했습니다.
- BLEU는 위에서 말했듯이 문장 기반이 아닌 corpus 기반 측정항목입니다.
그렇기 때문에 개별 문장을 평가하는 경우 성능은 그닥 좋지 않습니다. - 문장의 의미와 문법이 잘 파악되지 않습니다.
'not'과 같은 단어는 긍/부정을 바꾸기 때문에 중요합니다. 4gram 이하로만 고려하기 때문에 멀리 있는 not의 경우 무시되는 문제가 생깁니다. - 기능어와 내용어 간 구분을 못합니다. 번역을 할 때는 "a"와 같은 관사정도는 빼먹어도 번역에 큰 영향을 주지 않습니다.
하지만 BLEU는 내용어와 기능어를 구분하지 않기때문에 a와 같은 관사를 누락한 것과 "nasa"애서 a를 누락해 "nas"라고 번역한 것에 대해 동일한 페널티를 주게 됩니다
하루 정리
seq2seq 실습도 정리해야되는데 어제 밤샜더니 너무 졸립다. 어제 심장이 너무 뛰어서 밤 샘;; 커피 끊어야 할 듯
피어세션 시간에는 앞으로의 방향성? 등을 애기했는데 3일동안은 최성준 교수님 시간에 배운 reguralization기법들을 cnn classification에 적용하는 코드들을 구현해보기로 하고 , 나머지는 transformer관련 소소한 프로젝트?를 진행하기로 했다.
오늘 마스터클래스 시간에 주재걸 교수님이 해주신 말씀 중에 가장 기억에 남는 게 "공부 할 수 있는 원동력은 같이 공부하는 친구들"이라고 말씀하셨는데 새삼 와닿으면서 벅찬 얘기였다. 내가 이상한 거 질문해도 항상 같이 고민해주고 알려주는 도균 민준 정우 땡큐 얘네가 있어서 그래도 꾸역꾸역 공부하는 거 같다.
너무 졸립다. 논문도 읽어야하고 선대 공부도 해야되는데 ㅜㅜㅜㅜ
아 어제 조교님에게 개인적으로 질문 잘 하는 법을 질문 드렸었다. 되게 말장난 같은데 질문을 잘 하는 것도 중요한 커뮤니케이션 스킬인 거 같다.

'Naver Ai Boostcamp' 카테고리의 다른 글
| [DAY 20] self-supervised pretrained model - Bert , GPT (0) | 2021.02.20 |
|---|---|
| [DAY 19] Transformer (0) | 2021.02.18 |
| [DAY 17] RNN & LSTM & GRU (0) | 2021.02.17 |
| [DAY 16] Bag-of-Words & Word2Vec, GloVe (0) | 2021.02.15 |
| [DAY 15] Generative model (0) | 2021.02.05 |