📌 학습정리
- 시퀀스 데이터만의 특징, 종류, 다루는 방법
- CNN,MLP등과 RNN의 차이점 비교해보기
- BPTT를 수식적으로 이해하고 기울기 소실문제 발생 이유와 해결책 찾아보기
- seqential model의 한계점
- Transformer의 encoder, multi head attetnion 이해하기
1. 시퀀스 데이터
시퀀스 데이터란 음성, 문자열 , 주가와 같이 시간 순서가 있는 데이터를 얘기한다.
예를 들어 텍스트의 경우, 이전 문장 없이 그 다음 나올 문장을 예측하거나 완성하는 건 불가능하다.
그렇기 때문에 시퀀스데이터는 독립동등분포(i.i.d)를 위배하기 때문에 순서를 유지해주지 않으면 정보에 손실이 생겨 확률분포가 변해버린다.
앞으로 발생할 데이터의 확률분포는 이전 시퀀스의 정보를 가지고 조건부확률을 이용하여 표현할 수 있다.
"I love naver"라는 문장이 있다고 생각해보면 이 문장이 나올 확률을
우선 I라는 단어가 나와야한다.
I라는 단어가 나왔을 때, love라는 단어가 나와야한다.
I love 두 단어가 나왔을 때, naver라는 단어가 나올 확률가 같아진다.
$P(I,love,Naver) = P(Naver |I,love)\times P(love | I)\times P(I)$
일반화 시켜 길이가 t인 어떤 시퀀스 데이터가 있다면 조건부 확률을 이용하여 표현할 수 있다.

위 수식은 어떤 t시점을 표현하기 위해 1시점 즉 맨 처음부터 참고하고있다.
하지만 예를 들어 앞으로의 삼전 주가를 예측한다고 할 때, 10년 전의 삼전 주가정보까진 필요하지 않다.
우리는 꼭 처음부터가 아니라 우리가 보고싶은 이전시점까지만 고려해도 된다.
현재부터 우리가 보고싶은 이전 시점 사이의 고정된 길이를 $\tau $라고 하면 $\tau $만큼의 시퀀스만 사용하는 경우를 Autoregressive Model (AR($\tau$)) 자기회귀모델이라고 부른다.
미래를 예측할 때 고정된 길이만 고려하는 게 맞을까?
시퀀스 데이터를 다루기 위해서는 길이가 가변적인 데이터를 다룰 수 있는 모델이 필요하다.
예를 들어 어떤 소설을 데이터로 사용한다고 가정하면, 데이터 별 길이가 천차만별일 것이다.
게다가 어떤 문장에서는 맨 마지막 단어를 예측하기 위해 이전 3~4개의 단어만 고려해야할 수도 있지만, 엄청 긴 문장임에도 불구하고 맨 앞 단어를 고려해야하는 경우도 있을 수 있다.
이런식으로 각각의 시퀀스 시점에서 고려해야 할 데이터의 길이가 달라질 수 있다.
이전 정보를 제외한 나머지 정보를 $H_{t}$라는 잠재변수로 인코딩해 활용하는 latent autogressive model(잠재 AR 모델)을 사용해 이 점을 극복할 수 있다.
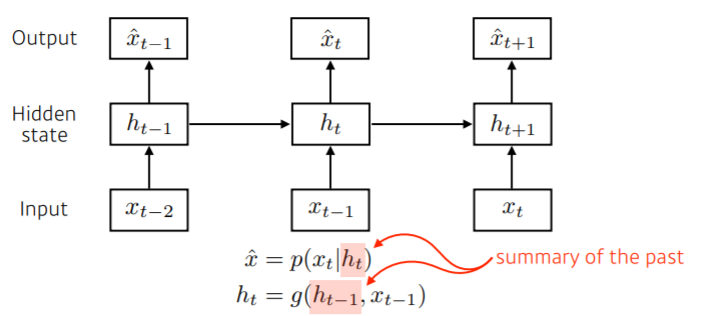
\begin{align}P(X_{t}) =P(X_{t}| X_{t-1}, H_{t})\end{align} .
위 식처럼 이전 시점 (t-1)의 정보와 나머지 정보들 $H_{t}$ , 2가지 정보들만 고려해 t시점에 대해 예측하게 된다.
H는 과거의 가변적인 많은 정보들을 고려해 잘 요약해놓은 것이라고 볼 수 있다.
2. Vanilla RNN
위와 같이 latent autogressive model을 반복해서 사용해 시퀀스 데이터의 패턴을 학습하는 모델을 Recurrent Neural Network (RNN)이라고 한다.
기본 구조는 MLP와 유사하지만 RNN은 이전 순서의 잠재변수 H와 현재의 입력 X를 활용하여 모델링한다.
입력으로 지금 시점의 정보 $X_{t}$와 이전 시점들의 정보가 담긴 잠재변수 $H_{t-1}$가 들어간다.
잠재변수인 $H_{t}$를 복제해서 다음 순서의 잠재변수를 인코딩하는데 사용한다.
RNN에서 은닉층에서 활성화 함수를 통해 결과를 내보내는 저 녹색박스를 셀(CELL)이라고 한다.
이전의 값들을 잘 요약하여 기억하는 메모리 역할을 하므로 메모리 셀, RNN셀이라고 표현한다.
메모리 셀이 출력층 방향 혹은 다음 시점의 메모리 셀에 보내는 값을 Hidden state라고 한다.
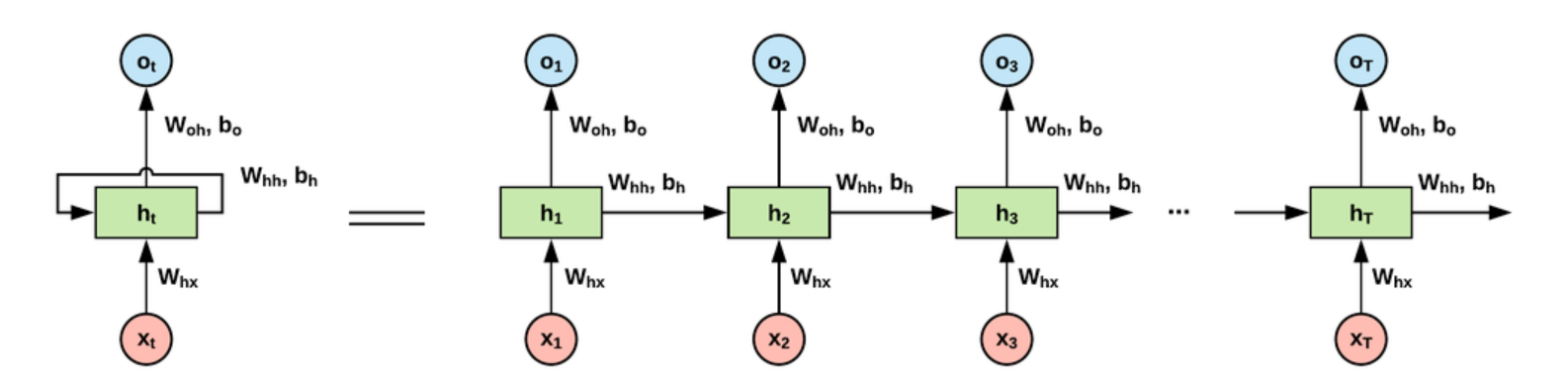
왼쪽처럼 하나의 재귀형태(rolled)로 나타낼 수 있는 이유는 저 그림을 잘 보면 모든 가중치가 같다.
위 수식으로 따지면 $W^{(2)} $ , $ W_{X}^{(1)}$ , $W_{H}^{(1)}$ 세 가중치는 변하지 않는다.
달라지는 것은 입력층 $x_{t}$와 그에 따른 $y_{t}$, 다음 메모리셀로 넘겨주는 계속해서 업데이트 되는 hiddent state다.

input으로는 t시점의 정보 , 이전 hiddent state를 받아 각각 가중치를 곱한 후 더해준다.
이후 활성화 함수를 통해 나온 결과값을 출력층 혹은 이후 레이어로 보내주면서, 업데이트 된 hidden state로 다음 RNN셀의 입력으로 보낸다.


코드로 구현을 할 때는 맨 처음 $x_{1}$일 때는 입력으로 주어지는 hidden state를 동일한 사이즈의 0으로 초기화 해준다.
그리고 torch에서 제공하는 rnn에 넣으면 나오는 output은 우리가 생각하는 softmax까지 취한 output이 아닌 hidden state가 출력된다. 정확하게는 두 가지가 출력되는데 맨 마지막 hidden state(1xd) 와 여태까지 생성되었던 hidden_state들이 쌓여있는 nxd 이렇게 두 가지가 출력된다.
➕ 그림을 이렇게 보니까 코드를 짤 때 어,, layer는 뭐고 input, output dim은 어떻게 되지? 하고 너무 헷갈린다.
RNN이라고 검색하면 나오는 그림들이 정직하게 input-hidden-output에다가 넣는 족족 나오기 때문이다...
- 우선 넣는 족족 나오는 게 아닌다. task에 따라 달라진다.
아래 빨간색 input의 개수가 input의 dimension , 위의 파란색 output의 dimension이 된다.

- one to many의 예 : image captioning 처럼 이미지 하나를 주었을 때 단어들의 시퀀스로 나온다.
RNN구조에서는 매 timestep마다 입력이 주어져야하는데 one-to-many의 경우, 사이즈는 같지만 0으로만 이루어진 텐서 혹은 벡터를 입력으로 넣어주게 된다.
- many to one의 예 : sentiment처럼 주었을 때, 단어들의 시퀀스를 넣었을 때, "공포"와 같은 하나의 단어로 출력해준다.
- many to many의 예 : input과 output의 dim이 다를 경우 예를 들어 기게변역이 있다.
전처리를 하면 물론 달라지겠지만 "내 이름은 오혜린" (3) -> "my name is ohhyerin"(4)
이 경우 한글로 된 문장이 모두 input으로 들어와야지만 영어로 된 문장을 출력할 수 있게 된다.
- many to many의 예 : 넣는 족족 나올 때를 얘기한다.
동영상 같은 경우 여러개의 이미지 프레임에 대해 여러개의 설명이나 자막을 결과로 반환하게 된다.
- layer는 뭐냐...? 그림에서 초록색으로 칠해진 hidden layer는 하나만 있는 게 아니다.

위 그림처럼 파란색으로 칠해진 hidden layer를 위로 여러 개 쌓을 수 있고, 그게 layer의 개수가 된다.
hidden dimension이란 rnn의 저 파란 부분은 MLP와 동일하다. 즉 input layer의 크기가 1x64였다면 64x256짜리 weight와 곱해져 1x256짜리 hidden_state를 만들게 된다. 여기서 256이 의미하는게 hidden_dimension이다.
3. RNN의 BTPP 및 문제점

Backpropagation Through Time (BPTT)라고 하며 RNN의 역전파 방법이다.
RNN의 역전파는 잠재변수 H의 연결 그래프에 따라 순차적으로 계산된다.
각 레이어마다 모두 동일한 웨이트이므로 n번만큼 누적으로 에러를 전파하고 학습시켜 업데이트하는 과정을 거친다.
BPTT를 통해 RNN의 가중치 행렬의 미분을 계산해보면

시퀀스의 길이가 길어질수록 저 파란색으로 밑줄쳐진 부분때문에 backpropagation 시 불안정해지기 쉽다.
여기 수식과 함께 엄청 잘 설명 되어있다.
활성함수를 ReLU를 쓴다면 1이기 때문에 계속 곱해져 기울기가 엄청 거지는 exploding gradient 문제가 생길 수 있다.
sigmoid를 쓴다면 1보다 작아 계속해서 곱해져 결국은 0에 달하는 vanishIng gradient 문제가 생긴다.
그러다 보면 time step이 커질 수록 앞쪽의 정보가 잘 학습이 안돼 충분히 전달이 되지 않는다.
이를 장기의존성 문제(Long-term dependencies)라고 한다.
4. LSTM(Long Short Term Memory)

"Cell state"를 추가해 Vanilla RNN의 단점을 극복한 LSTM이다.
cell state는 일종의 컨베이어벨트와 같은 역할을 하며 이전 정보들을 잘 요약하여 다음 은닉층으로 넘겨주는 역할을 한다.
forget gate , input gate , output gate , update cell로 총 4가지로 나눠볼 수 있다.
주재걸 교수님의 말씀으로는 굳이 따져보자면 cell state에 있는 정보는 좀 더 완전한 많은 정보들이 담겨있고, hidden state에는 cell state에 있는 정보를 한 번 더 필터링 한 내가 지금 당장 다음 단어를 예측하기 위한 정보들만 담겨있다고 하신다.
1 ) forget gate

시그모이드 함수에 의해 어떤 정보를 버릴지가 정해지는 즉, 기억을 삭제하는 게이트다.
현재 시점의 $x_{t}$와 이전 은닉층에서 넘겨준 hidden state $h_{t-1}$이 가중치 벡터와 곱해진 후 시그모이드 함수를 지난다. 시그모이드 함수는 0~1 사이의 값을 가지는데 0 은 "completely get rid of this" 완전 정보를 삭제하는 것을 의미하고, 1은 이 정보를 계속 가져가는 것을 의미한다. 시그모이드를 거쳐나온 output은 cell state인 $C_{t-1}$과 곱해져 어떤 정보를 가져가고 어떤 정보를 버릴 지 선택하게 된다.
2) Input Gate

현재 시점의 input으로 받은 새로운 정보들 중 어떤 정보를 저장할 지 , 즉 현재 정보를 기억하는 input gate다.
현재 시점의 $x_{t}$와 이전 은닉층에서 넘겨준 hidden state $h_{t-1}$이 가중치 벡터와 곱해진 후 두 활성함수를 거친다.
"input gate layer"라고 불리는 sigmoid layer는 어떤 값을 업데이트 할 지 정한다.
tanh layer는 cell state에 추가 될 수 있는 새로운 후보값인 $\widetilde{C}_{t}$를 정한다.
3 ) update cell

$C_{t-1}$을 새로운 $C_{t}$로 cell state를 업데이트한다.
forget gate , input gate에서 어떤 정보들을 가지고 갈 지 정했으니 그걸 반영해주기만 하면 된다.
cell state에 $f_{t}$값을 곱해 정보들을 잊어버린다.
input gate에서 sigmoid를 통해 얻은 $\widetilde{C_{t}}$와 tanh를 통해 얻은 $i_{t}$를 곱한 후 cell state에 더해줘 어떤 정보를 추가적으로 기억할 지를 업데이트한다. "new candidate values"라고도 한다.
4) output gate

현재 시점의 $x_{t}$와 이전 은닉층에서 넘겨준 hidden state $h_{t-1}$가 sigmoid를 거친 값을 $o_{t}$하자.
cell state가 tanh를 거쳐 -1에서 1 사이 값으로 표현된 값과 $o_{t}$를 곱해 무엇을 출력할지 결정한다.
이 값은 출력도 되고, t시점의 hidden state가 된다.
lstm에 필요한 가중치들은 따로따로 구해지는 게 아니다.
아래 그림과 같이 concat을 통해 하나의 가중치로 나타낼 수 있다.
실제로 pytorch를 이용해 구현을 할 때도, weight는 matrix하나로 표현되고 무조건 size중 하나가 4의 배수가 된다.

lstm parameter 가 엄청 헷갈리는데 아래 글을 추천한다.
medium.com/deep-learning-with-keras/lstm-understanding-the-number-of-parameters-c4e087575756
5. GRU (Gated Recurrent Unit)
조경현 교수님이 만드신 국뽕이 차오르는 GRU다. LSTM 경량ver. 이다.

LSTM과 다르게 cell state없이 hidden state로만 이루어져있으며 reset gate , update gate로 2개의 gate를 가진다.
Transformer는 19일차 강의에서 다시 설명할 거라 옮겼습니다. ^_^
피어세션
- 최성철 교수님께서 내준 self-study에 해당하는 데이터셋 클래스 짜기가 과제였는데, 압축해제 자체도 너무 오래걸려서 하지 못했다,,,
- 그래서 내려진 특단의 조치 !
- 조원들끼리 데이터를 모으고, 각자 데이터셋 클래스 부터 훈련, 테스트하는 과정까지 짜보기로 했다.
- 물론 하루만에 뚝딱은 불가하고 설날주간동안 해오기 - 데이터를 크롤링하는 코드
!pip install --upgrade git+https://github.com/Joeclinton1/google-images-download.git
!googleimagesdownload --keywords "레드벨벳 슬기" --limit 2 --format png --output_directory /content/drive/Shareddrives/TEAM23/RedVelvet_data --image_directory seulgi위 코드의 문제점은 100장까지밖에 안되다는 것이다...
그래서 키워드를 영어로 바꾸고 다른 폴더에 저장한 후, 이름이 없는 애들끼리 합치는 코드를 짰다.
정말 가독성 떨어지는 코드지만,,, 나름 이거한다고 os랑 shutil 많이 찾아봐서 도움이 됐다.
import os
import shutil
wendy1 = os.listdir("/content/drive/Shareddrives/TEAM23/RedVelvet_data/wendy1")
wendy = os.listdir("/content/drive/Shareddrives/TEAM23/RedVelvet_data/wendy")
wendy_exist = [name.split(".")[1] for name in wendy]
cnt = 0
for name in wendy1 :
src_name = "/content/drive/Shareddrives/TEAM23/RedVelvet_data/wendy1/"+name
tgt_name = "/content/drive/Shareddrives/TEAM23/RedVelvet_data/wendy/"+name
if name.split(".")[1] in wendy_exist : pass
else :
shutil.move(src_name ,tgt_name )
cnt +=1
print("이동한 사진:" , cnt)'Naver Ai Boostcamp' 카테고리의 다른 글
| [DAY 16] Bag-of-Words & Word2Vec, GloVe (0) | 2021.02.15 |
|---|---|
| [DAY 15] Generative model (0) | 2021.02.05 |
| [DAY 13] Convolutional Neural Networks (0) | 2021.02.04 |
| [DAY 12] 최적화 (1) | 2021.02.02 |
| [DAY 11] 딥러닝 기초 (0) | 2021.02.02 |