📌 학습목표
- Convolution의 정의, convolution 연산 방법과 기능 이해하기
- 그리고 Convolution, 입력을 축소하는 Pooling layer, 모든 노드를 연결하여 최종적인 결과를 만드는 Fully connected layer 로 구성되는 기본적인 CNN(Convolutional Neural Network) 구조에 대해 이해하기
- ILSVRC라는 Visual Recognition Challenge와 대회에서 수상을 했던 5개 Network 들의 주요 아이디어와 구조 학습
- Semantic segmentation의 정의, 핵심 아이디어에 대해 배웁니다.
- Object detection의 정의, 핵심 아이디어, 추가적으로 종류에 대해 배웁니다.
1. Convolutional Neural Networks
: convolutional layer , pooling layer , fully connected layer로 이루어져있다.
- convolution , pooling layers : 특징을 추출하는 역할을 한다.(feature extraction)
- fully connected layer : classfication과 같은 decision making 역할을 한다.
2. CONV 파라미터 개수 감 잡아보기
- 교수님 말씀에 의하면 모델을 봤을 때, 아 대충 파라미터가 몇 십만 단위겠구나~와 같은 파라미터의 개수를 느낌적으로 아는 것이 중요하다고 하셨다.
- 파라미터 개수 세기 : kernel_ size * kernel_size * input_channel * output channel
- output channel은 kernel의 개수와 같다. - Alexnet 파라미터의 개수를 계산해보자.
3. CNN의 역사
비전분야의 올림픽이라고도 불리는 이미지 인식대회 ImageNet Large Scale Visual Recognition Challenge ,
ILSVRC라고 불리는 대회의 1등 (2등도 껴있음 ㅎ)을 한 번 살펴보자.
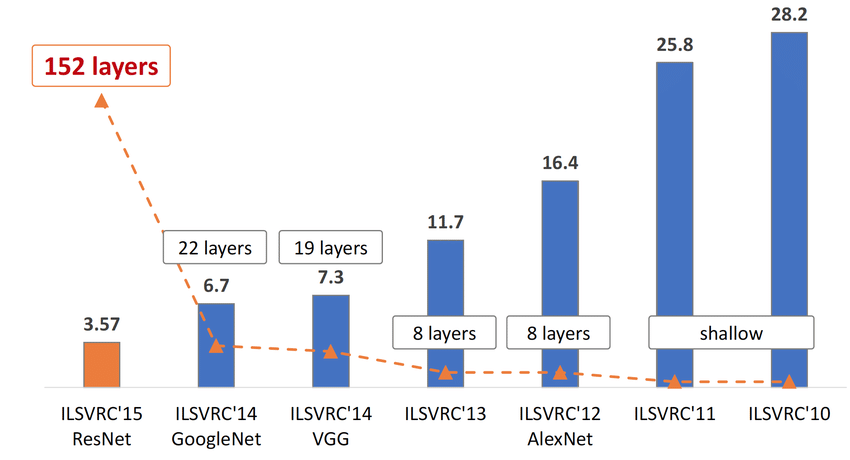
1 ) Alexnet

Alexnet 이전까지는 traditional cv인 svm과 같은 머신러닝기법들이 강세였다.
2012년 alexnet이 top-5 error rate를 10%대로 줄이면서 혜성같이 등장한다.
2등인 svm을 사용한 알고리즘과도 대략 10%차이가 나면서 딥러닝의 시대가 시작이 된다.
Alexnet의 특징은
- convolutional layer 5개 + fully connected layer 3개로 총 8개의 layer로 이루어져있다.
- 이 당시에는 layer가 8개만 되도 deep하다고 표현했다,,, - Relu의 사용
- 이전 힌튼 교수님의 논문에서 제시됐던 활성함수로 ALEXNET에 엄청 큰 기여를 한다. - GPU 2대를 병렬처리해서 사용
- 이 떄는 지금처럼 GPU가 좋지도 않았고, 널리 보급되지도 않았었다. - Local Respense Normalization 사용
- Overlapping pooling 사용
- data augmentation
- dropout
가장 큰 기여를 한 ReLU를 보면

- vanishing gradient problem을 극복한다.
- overfitting과는 다른 개념으로 layer가 깊어질수록 기울기가 점점 0에 가까워지는 현상을 얘기한다.
backpropagation을 하면서 layer를 거치고,거치고,거치고 또 거치다 보면 계속 gradient를 곱하게 되는데 sigmoid 같은 활성함수를 사용하면 0~1 사이의 값이 나와 결국 0에 가까워진다.
하지만 relu는 미분값이 0 아니면 1이기 때문에 기울기가 많이 손실되지 않는다.
- overfitting과는 다른 개념으로 layer가 깊어질수록 기울기가 점점 0에 가까워지는 현상을 얘기한다.

- optimize하기가 쉬워 빠르게 수렴한다.
- 왜 쉬울까? relu는 0보다 작으면 모두 0으로 처리해준다.
한 번 음수가 되면 그 노드는 더이상 학습하지 않는 것이다. 그렇기 때문에 연산량을 월등하게 줄여준다.
실제로 tanh와 비교했을 때 error가 0.25가 될 때까지 relu가 약 6배 더 빠르게 수렴한다.
- 왜 쉬울까? relu는 0보다 작으면 모두 0으로 처리해준다.
- 이런 점들로 인해 relu를 사용하면 generalization이 잘 된다. 그래서 아직까지도 잘 쓰이는 거 같다.
2. VGG Net

2014년도 2위지만, 우승자인 GoogLeNet보다 더 자주 쓰이는 거 같은 vggnet 이다.
- 3x3 covolutional filter를 사용했다.
- 가장 큰 특징!! 3x3은 주변을 같이 고려할 수 있으면서도 가장 작은 filter다. - 깊이를 19 layer까지 늘렸다.
- 3x3 덕분에 layer를 깊게 쌓으면서도 overfitting의 문제에서 벗어날 수 있었다. - fully connected layer를 1x1 conv layer로 대체했다.
-fclayer는 input의 크기가 고정되어있어, 모델에 들어가는 input size를 통일시켜줘야하지만 1x1 conv layer는 상관없기 때문에 crop을 사용하지 않고 input size가 통일되지 않아도 된다.
vgg의 핵심 3x3 filter에 대해 알아보자.
📌 3x3 convolution의 중요성
이전 Alexnet의 문제점은 filter size의 크기가 너무 크다는 것이다. 이게 왜 문제인가?
파라미터의 개수는 필터 사이즈 x 필터 사이즈 x 인풋 채널 수 x 아웃풋 채널 수이다.
여기서 필터의 사이즈가 크면 파라미터의 개수가 너무 많아지게 되고, overfitting의 위험이 있다.
필터 사이즈가 커야 팍팍! 줄일 수 있는 것 아닌가? NO,,,

5X5 kernel을 1번 쓴 것과 3x3 kernel을 2번 쓴 것은 동일한 size의 output을 내놓는다.
모두 동일한 차원이라고 정의할 떄
5x5를 1번 사용했을 때 파라미터의 개수는 5x5x128x128 이고,
3x3을 2번 사용했을 때 파라미터의 개수는 3x3x128x128 + 3x3x128x128입니다.
비교해보자면 25 x 128 x 128 vs 18 x 128 x 128로
3x3을 2번 사용했을 때 파라미터의 개수가 확 줄어들게 됩니다!
결국 사이즈가 작은 커널을 깊게 쌓는 것이 이득이라는 것이다.
3. GoogLeNet
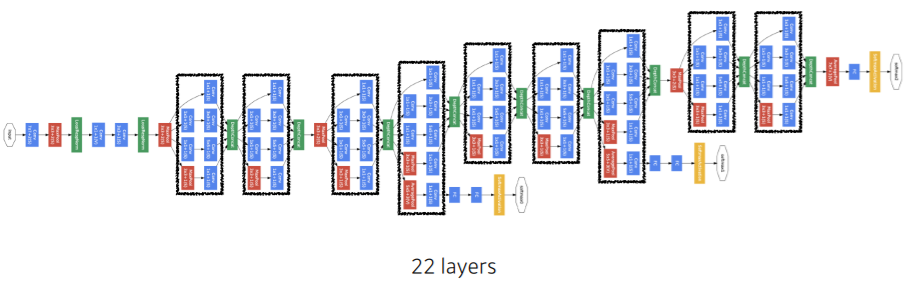
2014년도 ILSVRC 우승자이다.
layer를 22단까지 늘렸지만 vgg의 파라미터의 1/10도 안되는 충격적인 모델이다.
가장 큰 특징은 Inception block 그 자체,,,,
중간 중간 한 번씩 빼줘서 backprop이 잘되게 해주는 것도 있지만 뭐니뭐니해도 인셉션 모듈이 핵심!
위 그림의 검정색 네모 친 부분을 인셉션 모듈이라고 한다.

인셉션 모듈의 핵심은 1x1이다.
kernel size = 1로 딱 픽셀 하나만 보는 거다.
input에서 바로 3x3 conv를 거쳐 output channel의 수에 맞추게 되면, 파라미터의 개수가 급증한다.
이걸 방지하고자 1x1 conv를 넣어 채널의 수를 훅 줄여 HW사이즈는 유지하며 파라미터의 수를 줄여주었다.
예를 들어 input 채널이 256, output channel이 480인 경우, 왼쪽부터 차례대로
1 ) 1x1 filter를 사용해 channel의 수를 128로 줄인다. -> 1x1x256x128
2 ) 1x1 filter를 사용해 channe의 수를 128로 줄인 후 , 3x3 filter를 사용해 192로 줄인다. -> 1x1x256x128 + 3x3x128x192
3) 1x1 filter를 사용해 channe의 수를 32로 줄인 후 , 5x5 filter를 사용해 96로 줄인다. -> 1x1x256x32 + 5x5x32x96
4 ) 3x3 pooling 한 이후 1x1 conv를 사용하여 channel의 수를 64로 줄인다. 1x1x256x64
참고로 pooling은 가중치가 없다.
그러면 결국 동일한 HW사이즈에 각각 채널이 128 , 192 , 96 , 64가 모여 채널의 수가 480인 output이 나온다.
만약 256에서 바로 480으로 가려고 했다면, 제일 작은 3x3 filter를 쓰더라도 256 x 480 x 3 x 3으로 3배가량 커진다.
1x1 convolution의 장점에 대해 더 얘기해보자.
📌1x1 convolution
- dimension reduction (채널 감소)

1x1을 사용하면 feautre map의 비교적 적은 파라미터 수만으로도 HW사이즈는 그대로 유지하면서 채널의 수를 줄일 수 있다.
- 파라미터 개수의 감소

깊이는 늘리면서 파라미터의 개수는 대폭 줄일 수 있다.
한 번 1x1을 거쳐 채널을 줄였다가 원래 채널로 돌아가게 되면 거의 3배 가량의 파라미터의 개수를 줄일 수 있다.
파라미터의 개수가 줄어들면 모델이 복잡해지지 않으며, overfittng의 위험이 줄어든다.
위 그림처럼 채널을 줄였다가 다시 키우는 것을 bottleneck이라고 한다.
이는 resnet에서도 쓰인다.
- 비선형성 증가
- 1x1을 쓰면 깊이를 늘릴 수 있다.
그럼 layer마다 활성함수를 사용할 수 있고, 그렇게 비선형성을 높여 더 어려운 문제도 잘 판단 할 수 있게 만든다.
4. Resnet
2015년도 우승자로 이미지 분류 성능이 사람을 뛰어넘었다.

가장 큰 특징은 skip connection 구조의 residual block을 사용했다는 점이다.
레즈넷부터는 이전 모델들과는 문제가 조금 달라진다.

모델을 깊게 쌓으면 마냥 좋을 줄 알았는데 더 깊은 56 layer가 20 layer보다 성능이 좋지 않다.
단순한 overfitting의 문제는 아니다. 깊어질수록 acurracy가 증가하지 않고 어느 순간 급격하게 떨어지는 degradation문제를 해결하기 위해 residual block이라는 개념을 제안한다.

mapping을 통해 나온 출력을 H(x)라고 할 때, 우리의 목표는 가중치나 편향의 학습을 통해 최적의 H(x)를 얻는 것이다.
H(x) 를 얻는 것을 목표로 하는 것보다 H(X) - X 즉 F(X) 변화량을 얻을 수 있도록 학습하는 것, 최적화하는 것이 훨씬 쉽다고 한다.
몇 개의 layer를 스킵하는 것을 short connection 이라고 한다.
resnet에서는 입력에서 바로 출력으로 연결되는 x : identity mapping을 통해 short connection을 보여주고있다.
이런 identity short-connections 은 따로 파라미터를 추가해준 것도 아니고 복잡하지도 않다.
1) plain net과 비교했을 때 깊이가 깊어져도 최적화하기 쉽다.
2) 깊이가 깊어져도 쉽게 향상된 accuracy를 보일 수 있다.
라는 장점을 가진다.

그냥 더해주는 simple shortcut과 채널을 맞춰주기 위해 사영을 시켜준 후 더하는 projected shortcut이 있다.
교수님 말씀에 의하면 projected shortcut은 잘 사용하지 않는다고 한다.
그리고 batch normalization이 relu 이전에 오는데 둘의 순서에 관해서는 말이 많다고 한다 ㅎㅎ

resnet도 1x1 convolution을 이용하여 bottleneck구조를 가진다.
파라미터의 수를 대폭 줄이고 깊이를 늘려 비선형성을 증가시킬 수 있다는 이점이 존재한다.
수업시간에 다루지는 않았지만 googlenet , resnet 모두 GAP 방식을 채택했다.

Global Average Pooling은 각 channel의 평균을 구해 feature를 1차원으로 만들어 준다.
input size가 고정적이어야 하는 fc layer의 단점을 극복할 수 있어 사용된다고 한다.
5. DenseNet

레즈넷이 skip connection을 통해 두 행렬을 인덱스와 채널이 같은 픽셀끼리 더했다면
덴즈넷은 skip connection을 통해 두 행렬을 concatenation 시켜 버린다.

이전 레이어의 피처가 계속해서 concat된다.
그러면 6으로 시작했던 채널수가 결국 22까지 급증한다.
채널이 너무 급증하면 파라미터의 개수가 늘어나는 것은 아닐까?

그걸 대비해서 1x1 convolution을 해준다.
transition layer에서 1x1 covolution을 해주어 채널 수를 대폭 줄여주고 , pooling을 통해 가로,세로 사이즈도 줄여준다
신기하게도 BN - ReLU - Conv순으로 이뤄진다.
cnn모델이 단순히 이미지 분류에만 쓰이는 것은 아니다.

segmentation과 object detection에 대해 배워보자.
4. semantic Segmentation
이미지 내에 있는 각 픽셀들에 대해 classification을 해 어떤 의미있는 단위들로 표현하는 것이다.

위 그림의 각 픽셀에 대해 클래스를 예측한 후 사람, 자전거,배경과 같은 의미있는 객체들로 표현한다.
이게 어디 쓰일까 싶지만 요새 주식을 넣을까 고민하고 있는 테슬라의 "자율주행"과 같은 곳에 쓰인다.
무엇이 사람이고, 신호등이고, 표지판인지 알아야 주행을 안전하게 할 수 있기 때문에 필수다.
semantic segmentation의 핵심은 바로 FCN : Fully Convolutional Network이다.
기존 네트워크에서는 분류를 하기 전 마지막 layer를 fully connected layer 를 사용했다.
fully connected layer는 input size가 고정되야하면서, 위치정보를 잃어버린다는 단점이 있다.

이를 극복하고자 나온 게 fully convolutional network이다. 1x1 convolution layer로 바꿔주는 것이다.
이 과정을 convolutionalization라고 한다.
1x1을 사용하게 되는 이유는 무엇일까?

파라미터의 개수는 똑같기때문에 연산량 감소의 문제는 아니다.
1x1을 사용하게 되면
- input 차원이 자유로워진다. fully connected 처럼 고정되어있지 않으므로 어떤 사이즈의 input도 가능하다.
- 근처에 누가 있는지와 같은 위치정보를 대략적으로 가지고 있다.
- 아래와 같이 class의 score와 위치정보를 담고있는 heatmap을 얻을 수 있다.

마지막 channel 수는 class의 수와 같다.
각 channel은 하나의 클래스를 대표해 만약 위와 같은 경우 저 채널이 고양이를 나타낸다면 그 채널 내 고양이에 해당하는 픽셀값들이 높게 나탄다.
heapmap은 대략적인 굵직한 coarse한 정보를 가지고 있기 때문에, 조금 더 디테일하게 segmentaion하기 위해서는 다시 upsampling을 해줘야한다.
upsampling 방법에는 unpooling , deconvoluion 등의 방법이 있지만, 여기서 "deconvolution"이라는 개념이 사용된다.

정확히는 아니지만 convolution의 역연산이라고 생각하면 편하다.
upsampling을 통해 각 클래스에 해당하는 coarse한 heatmap을 원래 사이즈로 키워 dense하게 만들어준다.
5. Object Detection
: 어떤 물체가 어디있는 지 알아내는 것으로 classification + localizaion을 함께 해야 된다.

이전에는 SIFT , HOG와 같은 영상처리 기법으로 해결하다 딥러닝의 시대가 열리면서 cnn을 이용하여 해결하게 되었다.
객체를 검출하는 단계와 분류를 하는 단계가 순차적으로 이뤄지는 two stage detection 모델과 두 태스크를 한 번에 하는 one stage detection 모델로 나눠진다.
1) RCNN

two stage detect의 조상급이다.
selective search라는 알고리즘을 통해 대략 2000개의 region proposal, 즉 물체가 있을 거 같은 지역들(ROI)을 뽑아낸다.
그 후 input size를 고정시켜주고, 아래 과정을 2000개의 ROI에 대해 진행한다.
각 ROI들에 대해 convnet을 거쳐 feature를 뽑아내고 bounding box를 학습해 박스의 모양과 위치를 재조정한다.
SVM을 통해 분류해 클래스를 계산한다.
느리다. 그것도 엄청나게 한 장을 처리하는데 대략 1분이 걸린다.
selective search 자체도 딥러닝을 이용한 게 아니라 느리고, 2000개의 ROI마다 다 CONV를 학습하기 때문에 시간이 오래걸린다. 또 proposal에 대해 연산을 공유하지않고, 개별적으로 연산을 진행하기 때문에 느리다.
학습시키기 어렵다.
end-to-end training이 아니다. 그렇기 때문에 backpropagation이 끝까지 진행되지 않아 모든 가중치를 업데이트 시킬 수 없다.
2 ) sppnet
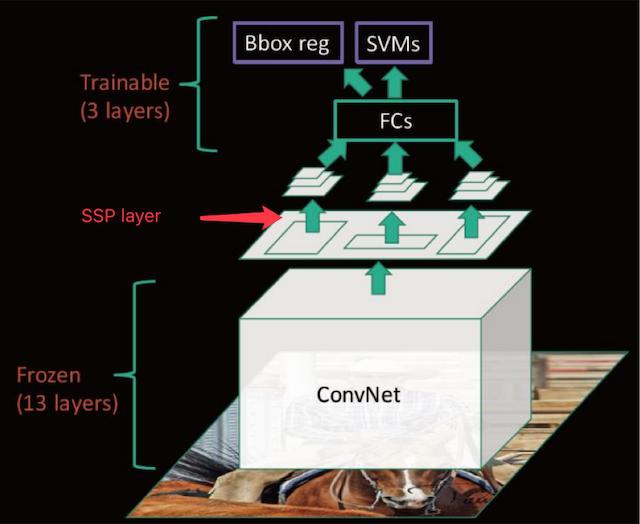
RCNN을 극복하기 위해 나온 모델이다.
RCNN 의 2000개의 ROI들이 각기 따로 CONVNET을 학습하는 점을 극복했다.
fclayer 때문에 input size가 고정되었던 RCNN과는 달리 input size에 상관없이 conv를 한 번만 학습한 후
spaital pyramid pooling을 통해 fc layer의 input을 맞춰준다.
그래도 느리다.
좋아졌긴 하지만 selective search -> convnet -> bbox regression -> svm 의 multi stage인 건 똑같다
SSP를 backpropagation 하는 것이 불가능해 SSP layer 이전의 가중치는 업데이트 시킬 수가 없다.
3 ) Fast RCNN

기존 모델들이 분류를 위해 SVM을 사용하는 것을 탈피했다.
Softmax , multi task loss를 사용해 single stage로 훈련하기 때문에 end-to-end 학습이 가능해졌다.
이미지를 input으로 넣어 convnet을 거쳐 나온 feature map에 selective search를 통해 만들어진 region proposal을 사영시켜준다. 이후 ROI pooling을 거쳐 고정된 feature vector를 뽑아낸다
이후 feature vector 들은 fc layer를 거친 후 class를 계산하는 softmax layer와 bounding box의 위치를 조절하는 bbox regressor layer로 나눠진다.
svm을 탈피하고 single stage로 모든 레이어가 학습이 가능해졌지만 , 아직 region proposal을 selective search에서 진행하기 때문에 느리다는 한계점이 존재한다.
4 ) faster rcnn

드디어 region proposal도 딥러닝으로 하게 되었다.
localization을 하는 Region Proposal Network와 Convnet을 합쳐 하나의 네트워크로 만들었다.
pretrain 된 convnet에서 뽑은 feature map을 이용하여 region proposal을 뽑고, 그걸 이용하여 classfication과 bounding box regression을 진행한다.
RPN은 bounding box를 어떻게 만들까? 여기서 "anchor box"라는 개념이 나오게 된다.

다양한 sclae과 aspect ratio를 reference box로 준다.
bounding box들에게 물체가 있을법한 모양인 템플릿을 주고 여기서부터 시작해! 라고 하는 것이다.
sliding window방식으로 지나가며 bounding box에서 물체가 있는지에 대한 정보와 box의 위치정보를 계산한다.
1x1 conv를 거치게 되는데 이때 2x9 channel에는 9개 모양에 대한 물체 유무정보가 , 4x9 channel에는 9개의 모양에 대해 박스의 중심 x,y좌표,높이,너비에 대한 정보가 계산된다.
5) YOLO
YOLO부터는 드디어 one stage model로 classification 과 localizaion을 같이 하게 된다.
그렇기 때문에 이전 모델과 비교도 안되게 빠르다

우선 SxS 그리드로 이미지를 나눠준다. 그러면 그리드 내 중심이 존재하는 박스들이 각각 그리드마다 할당된다.
이후 박스마다 5개의 정보를 계산하는데, 물체의 유무 , box의 높이,너비,x,y좌표를 학습한다.
각 그리드 셀마다는 C개의 클래스에 대한 확률을 계산한다.
마지막에 SxSx(Bx5+C)모양의 tensor를 통해 객체를 탐지하고 학습한다.
피어세션
1. 질의응답
오늘 좀 활발한 질의응답이 오갔다. 그 중에서도 도움이 된 몇 개 뽑아보자면
- dropout : 노드 일부를 비활성화시켜주다 = 특정 채널을 영벡터로 만들어준다.
- regularization : cost fuction에 가중치의 합도 넣어줘 단순히 코스트가 작아지는 방향으로 진행되는 것이 아닌 가중치들이 작아지는 방향으로 진행을 하게 된다. 특정 가중치가 비이상적으로 커지고 학습에 영향을 끼쳐 일반화되지 않는 것을 방지한다.
2. 알고리즘
dic = dict()
n = int(input())
for idx in range(n):
age , name = input().split()
if age in dic.keys(): dic[age].append([idx, name])
else : dic[age] = [[idx , name]]
for k, v in sorted(dic.items() , key = lambda t:int(t[0])):
for idx , name in sorted(v) :
print(f"{k} {name}")
d = dict()
for idx in range(1,9):
score = int(input())
d[idx] = score
sorted_dic = sorted(list(d.items()) , key = lambda t : t[1] , reverse = True)
five_dic = sorted(sorted_dic[0:5], key = lambda t : t[0] )
sum = 0
for i in five_dic:
sum += i[1]
print(sum)
for i in five_dic : print(i[0] , end=' ')
핑계를 좀 대보자면 시간이 없어서 호다닥 풀었는데, 보윤님 코드가 진짜 파이써닉하다,,,
top5 = sorted([(int(input()), str(i)) for i in range(1, 9)], reverse=True)[:5]
score, num = zip(*top5)
print(sum(score))
print(" ".join(sorted(num)))
실습 관련해서는 학습정리를 어떻게 정리해야할지 감이 잘 안온다.
COLAB, 가상환경 쓰는 게 너무 어려워서 익숙해지려고 해봐도 계속 연결이 끊기거나 데이터가 옮겨지지가 않거나 하는 등 계속 멀어진다,,,,ㅜㅜ
'Naver Ai Boostcamp' 카테고리의 다른 글
| [DAY 15] Generative model (0) | 2021.02.05 |
|---|---|
| [DAY 14] Recurrent Neural Networks (0) | 2021.02.05 |
| [DAY 12] 최적화 (1) | 2021.02.02 |
| [DAY 11] 딥러닝 기초 (0) | 2021.02.02 |
| [DAY 10] 시각화 / 통계학 (0) | 2021.01.30 |