Week7은 Further question 중심으로 학습정리하기
📌 모델의 시공간
Further Question
1) 이번 강의는 lightweight modeling과 어떤 관계가 있을까? (이 강의를 만든 목적은 무엇일까?
모델의 시간 & 공간복잡도를 줄이는 것도 경량화의 목적 중 하나이다.
시간복잡도와 공간복잡도는 trade-off가 된다.

compression model은 architecture를 바꿔야 하는 문제이므로 NAS 방법론 중 하나로 바라볼 수 있다.
2) regular convolution 대신 depthwise seperable convolution을 사용해서 계산상의 가장 큰 이득을 보는 경우는 언제일까?
depthwise seperable convolution 이란 ?
depthwise convolution 이후 pointwise convolution을 진행하는 conv기법이다.

각 채널별로 채널이 1인 kernel을 이용해 계산한 후 (depthwise) , 1x1 pointwise 연산을 한다.
3x10x10 featuremap을 16x10x10 featuremap으로 만들기 위해서
depthwise : (3x3x1)x3
pointwise : (1x1x3)x16
파라미터의 개수는 75 , 계산 수는 75x10x10 = 7500이 된다.
일반 conv의 경우는 3x3x3xx16으로 파라미터는 432 , 계산 수는 43200번이 된다.
depthwise seperable conv 로 계산을 하면 계산량을 5~6배 정도 줄일 수 있다.
계산상의 가장 큰 이득을 보는 경우는,,, 내 생각에는 채널이 갑자기 늘어날 때 아닐까 싶다.
3x3x10 에서 3x3x512로 featuremap을 만들 때
일반 conv는 3x3x3x512 = 13824
depthwise seperable conv 는 3x3x1x3 + 1x1x3x512 = 1563 의 경우 계산량을 대략 10배로 줄일 수 있다.
3) (동전 말고) 주사위의 경우에는 maximum entropy가 얼마나 될까?
어떤 사건의 확률이 매우 높으면 그 사건이 발생해도 적은 정보를 얻는다. 반대로 확률이 매우 낮은 사건은 발생하면 훨씬 유용한 정보를 제공한다. 즉 정보량은 확률에 반비례한다.
엔트로피틑 실제로 한 사건이 일어났을 때, 얻을 수 있는 평균 정보량을 의미한다.
최대 엔트로피는 uniform distribution을 따를 때를 얘기한다.
주사위를 던질 떄는 보통 앞,뒷면이 동일한 확률 $\frac{1}{2}$을 따라 발생한다고 가정한다.
이 경우 maximum entropy가 1이 된다.

그러면 주사위의 경우에는 각 6가지의 경우에 대해 사건의 확률이 1/6이 된다.
동전일때보다 주사위일 때 각 사건이 발생할 확률이 낮아졌으므로, 엔트로피는 더 커질 것이다.
실제로 계산을 해보면 $6 \times \frac{1}{6} log_{2}6$ 으로 2보다 커진다.
교수님의 설명에 따르면 경우의 수가 증가한다는 것은 엔트로피가 증가한다는 것과 동일하다고 한다.
그런 관점에서 봐도 동전에서 주사위가 되면 경우의 수가 증가하므로 자연스럽게 엔트로피도 증가하는 게 맞는 거 같다.
ToyCode
- torch-sensor : 올바른 차원의 텐서끼리 연산하는지 확인함
!pip install tensor-sensor[torch]
W = np.array([[1, 2], [3, 4]])
b = np.array([9, 10]).reshape(2, 1)
x = np.array([4, 5]).reshape(2, 1)
h = np.array([1,2])
# try is used just to catch the exception and extract the messages
try:
with tsensor.clarify():
W @ np.dot(b,b.T) + np.eye(2,2)@x
except BaseException as e:
msgs = str(e).split("\n")
sys.stderr.write("PyTorch says: "+msgs[0]+'\n\n')
sys.stderr.write("tsensor adds: "+msgs[1]+'\n')
- profiler : 컴퓨터 자원의 사용량 모니터링을 통해 누가 자원을 많이 잡아먹고 있는 지 알 수 있다.
with profiler.profile(record_shapes=True) as prof:
with profiler.record_function("model_inference"):
model(inputs)
# cpu_memory_usage 기준으로 정렬, 5개만 보여줌줌
print(prof.key_averages().table(sort_by="cpu_memory_usage", row_limit=5))
# cpu_time_total 기준으로 10개만 보여줌
# group_by_input_shape : inpytu_shape를 보여줌
print(prof.key_averages(group_by_input_shape=True).table(sort_by="cpu_time_total", row_limit=10))ㅕ
📌 알뜰히 : 압축
Further Question
1) 이번 강의는 lightweight modeling과 어떤 관계가 있을까? (이 강의를 만든 목적은 무엇일까?)
문장이나 데이터를 줄이면 압축했다라고 표현한다.

허프만 코딩이란 등장빈도가 높은 단어는 짧은 길이로 인코딩하고, 등장빈도는 낮은 단어는 길게 인코딩한다.
정확하진 않지만 엔트로피 관점에서 생각해볼 수 있을 것 같다.
등장빈도가 높은 단어는 정보량이 낮으므로 짧은 단어로, 등장빈도가 낮은 단어는 정보량이 높으므로 긴 단어로!
2) 이상적인 (=성능좋은모델) 경우와 현실적인 (=성능나쁜모델) 경우의 서로 다른 P(i)와 Q(i)를 가정하고 KL divergence를 다시 계산해보자.
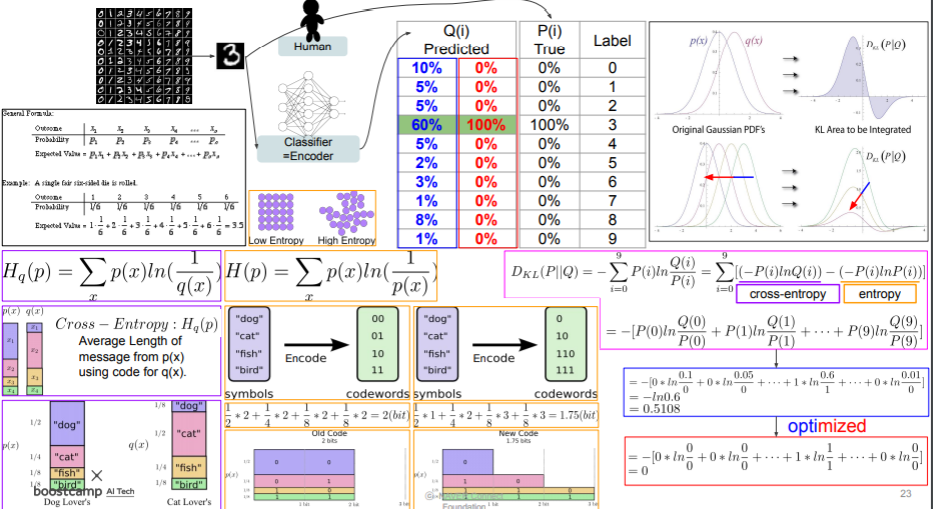
와! 여긴 정말 두달 내내 몰랐던 게 한 번에 쑤욱! 내려가는 느낌! 여기서 좀 감탄했다.
여태까지 왜 entropoy가 lower bound인지 몰랐는데 이제서야 이해간다.
cross entorpy는 q라는 분포를 가지는 codebook을 가지고 p를 해석했을 때의 평균길이라고 한다.
KL Divergence를 생각해보면 이는 p,q간의 cross entropy와 p의 엔트로피로 나눌 수 있는데
p라는 codebook을 가지고 p를 해석하면 새롭게 아는 사실(정보량)이 없으니까 당연히 엔트로피가 0이 되고, lower bound일 수 밖에 없게 되는 거 같다,,,!
p의 분포와 q의 분포가 비슷할수록 정보량이 적어지기때문에 엔트로피가 적어진다.
3) 이 압축률은 어떻게 해서 얻어진 걸까? (p 30)

Pruning + Quantization + Huffman coding을 한 것이 아닐까?
Toy Code
- torch -> onnx -> tflite
# onnx 이용
torch.onnx.export(model.cpu(), dummy_input.cpu(), "alexnet.onnx", verbose=True,
input_names=input_names, output_names=output_names)
# pb 저장
tf_rep.export_graph('/content/gdrive/MyDrive/model.pb') # 233MB
import tensorflow as tf
#pb 불러와서 tflite에 맞게 변환
converter = tf.compat.v1.lite.TFLiteConverter.from_frozen_graph(
'/content/gdrive/MyDrive/model.pb',
input_arrays=input_names,
output_arrays=output_names,
)
converter.target_spec.supported_ops = [
tf.compat.v1.lite.OpsSet.TFLITE_BUILTINS,
tf.compat.v1.lite.OpsSet.SELECT_TF_OPS,
]
tf_lite_model = converter.convert()
with open('/content/gdrive/MyDrive/model.tflite', 'wb') as f:
f.write(tf_lite_model) # 14KB
# tflite로 새롭게 저장시 14kb로 줄어듬
'Naver Ai Boostcamp' 카테고리의 다른 글
| [03/29] P Stage Start ! (0) | 2021.03.30 |
|---|---|
| [Day 38] 빠르게 & 가지치기 (0) | 2021.03.28 |
| [DAY 36] OMG 왜 안했누 (0) | 2021.03.26 |
| [DAY 35] Multi-modal & 3D Understanding (0) | 2021.03.25 |
| [DAY 34] Instance/Panoptic segmentation & Conditional generative model (2) | 2021.03.17 |