영어논문 스터디의 스타트를 내가 맡게 되었다.
이번에 내가 준비한 논문은 CNN 모델의 조상격인
ImageNet Classification with Deep Convolutional Neural Networks
알렉스넷이라고 더 잘 알려져있는 모델이다. PPT로 설명을 해보자


비전 분야의 올림픽이라고도 불리는 ILSVRC라는 이미지 인식 대회가 있는데 imagenet에서 제공하는 이미지 subset을 모델이 얼마나 잘 인식하는지를 평가하는 대회입니다.
2012년도 ILSVRC 대회에 2등과 10% 이상의 압도적인 성능차이를 보이며 혜성같이 alexnet이 1등을 손에 거머쥐게 됩니다. 왜 알렉스넷이냐!하면 논문의 제 1저자 이름이 알렉스이기 때문이죠 ㅋㅋㅋㅋㅋ
그 전년도인 2011년도에 우승을 했던 svm머신러닝 알고리즘과 대략 10% 정도 차이가 나면서 사람들에게 커다란 충격을 안겨주게 됩니다.
2012년도, 이때부터 전통cv기법은 거의 사라지며 딥러닝의 시대가 시작됩니다.
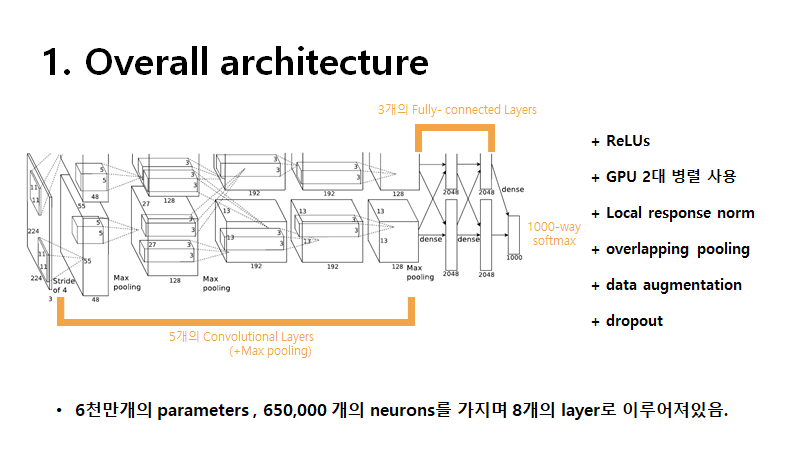
전체적인 구조를 먼저 살펴보자면 5개의 convolutional layers와 3개의 fully-connected layer 인 총 8개의 layer로 이루어져있으며 6천만개에 달하는 parameter를 가지고 있습니다.
특징으로는 활성함수로 relu를 사용하고 overlapping pooling 사용 , gpu 2대를 병렬처리했다는 것입니다.
local response라는 normalization을 해주었는데 지금은 잘 쓰이지 않는 기법이라고 합니다.
overfitting을 방지하기 위해 data augmentation 과 dropout을 사용했습니다.
이제 더 자세히 알아봅시다!

2011년도까지는 알렉스 팀은 CIFAR-10데이터로 훈련을 시켰습니다.
논문에서 사용된 data set을 보면 라벨링이 되어있는 ILSVRC-2010의 데이터를 주로 사용했다고 합니다.
120만개의 train set , 50,000개의 validation set ,150,000개의 test set 사용했습니다.
좋은 훈련을 위해서는 이미지 전처리가 필요하죠!
IMAGENET에서 제공되는 이미지가 크기 가로,세로 사이즈가 다 다릅니다.
그래서 다 256X256으로 rescaling과 crop을 진행해서 모든 이미지를 256x256x3으로 통일했습니다.
이외의 preprocessing은 하지 않았다고 하네요.

알렉스넷의 특징이라고도 할 수 있는 구조는 논문에서는 크게 4가지로 구분 지을 수 있습니다.
순서대로 설명을 한 번 해보죠!

이 이전에는 활성함수 activation fuction으로는 tanh , sigmoid 를 썼습니다.
하지만 알렉스넷에서는 아래의 논문에서 제시됐던 activation fuction으로 ReLUs 를 사용하였습니다.
V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proc. 27th
International Conference on Machine Learning, 2010.
이 이후로 지금까지도 거의 classification에서는 ReLU가 사용되죠!!
CIFAL-10을 가지고 layer가 4개짜리인 모델에 테스트를 해봤을 때 오답률 25%에 근접하기위해 필요한 에폭 횟수가 tanh를 사용하였을 때는 36번? relu를 사용했을 땐 6번? 정도로 약 6배 정도 차이가 나는 것을 확인할 수 있습니다.
즉 relu가 6배 더 빨리 수렴한다는거죠!
둘 다 정규화는 진행하지 않았고, 학습률은 각각의 모델에 최적화된 학습률을 사용하고 다른 조건은 다 동일하다고 합니다.
논문에서는 tanh를 사용했다면 우리는 large neural network를 못 썼을거다,,,,라고 하네요
tanh , sigmoid같은 전통적인 방식에서 탈피한게 ALEXNET이 처음이 아니라고 하는데
K. Jarrett, K. Kavukcuoglu, M. A. Ranzato, and Y. LeCun. What is the best multi-stage architecture for
object recognition? In International Conference on Computer Vision, pages 2146–2153. IEEE, 2009.
위의 논문에서도 |tanh|를 사용해서 전통적인 방식을 사용하지 않았다고 합니다.
하지만 위의 방식은 overfitting을 방지하기 위해 사용한거지 수렴속도를 높히기 위해 relu를 쓴 알렉스넷과느 다르다고 하며 빠른 속도는! 모델의 성능에 큰! 영향을 끼친다고 하면서 다음장으로 넘어갑니다.

train 당시 사용한 gpu가 GTX580GPU로 메모리가 3GB였는데 1.2million의 데이터 셋을 훈련시키기에는 턱없이 부족해
gpu 2대를 병렬처리(parallelization)했다고 합니다.
이 이후 gpu로 딥러닝을 하게 되며 nvidia가 엄청 부럽네요 ㅠ
kernel, neuron등을 gpu1,2에 각각 반씩 나눴는데 논문에서는 additional trick을 사용했다고 하는데 어떤 trick을 사용했나 살펴보면 특정 layer에서만 gpu가 communicate할 수 있게 했다고 합니다.
이게 무슨 뜻!이냐 하면 예를 들어 설명해보면 1,2,4,5 번째 conv layer 를 보면 같은 gpu내에서만 kernel을 사용하여 feature map이 나오는 것을 확인할 수 있습니다.
하지만 3번째 conv layer나 fc-layer들을 보면 gpu와 상관없이 두 대의 gpu에서 모두 kernel을 사용하여 feature map이 나온다든지 그 다음 fc가 나오는 것을 확인할 수 있습니다.
gpu와 kernel 관련해서 하고 싶은 얘기가 더 있지만 뒤에 넘어가서 하도록 하겠습니다!

논문과 관련된 설명은 아니고 local response normalization에 관한 얘기입니다.
저 그림을 계속 보면 교차로 사이사이에 회색 점이 있는 착시현상?이 보이게 됩니다. 실제로 있는 게 아닌데 말이죠!
이런 현상을 lateral inhibition이라고 부르는데 실제 뇌세포의 증상으로 강한 뉴런의 활성화가 근처 다른 뉴런의 활동을 억제시키는 현상이라고 합니다.
만약 주변의 값들은 다 1이고, 특정 값만 100이라고 하면 근처 값들도 커져 보이는 현상을 얘기하는 거 같습니다.
논문에서는 실제 뉴런에서 일어나는 현상을 보고 local response normalization이라는 걸 생각했다고 합니다.

relu함수는 f(x) = max(0,x)으로 상한이 없는 unbounded함수입니다.
그렇기에 값이 무한으로 커질수도 있어서 더욱 더 LRN이 효과적이라고 하는데요
LRN은 주변의 값에 비해 너무 큰 특정 값에 비해 overfitting 되는 것을 막고 gneralization 즉, 일반화 하는데 도움이 된다고 합니다.
식만 보면 식은 땀이 나지만 천천히 그림과 같이 예를 들어 설명해보면 feature map에 대해 kernel을 convolution 해서 나온 결과를 kernel map이라고 ㅎ해봅시다.
예를 들어 10번째 kernel map 의 (2,5) 픽셀을 생각해봅시다!
논문에서는 n=5 즉 자신을 포함해 인접한 5개의 kernel 의 같은 spatial position을사용한다고 써있습니다.
그러면 8번째 kernel map의 (2,5) 값부터 12번째 kernel map 의 (2,5)값까지의 제곱의 합을 구합니다.
거기에 특정 하이파라미터인 alpha를 곱하고 k를 더해 beta 제곱을 해준 값으로 10번째 kernel map 의 (2,5) 값을 나누면 새로운 값이 나오게 되죠!. 이 과정을 local response normalization이라고 하고 10번쨰 kernel map의 (2,5) 값은 방금 얘기한 그 새로운 값이 나오게 되고 이를 논문에서 사용한 용어로 얘기하면 i번째 b_x,y 겠네요

parameter의 수가 너무 많아지면 overfitting의 위험이 있어 이를 방지하고자 pooling 기법을 사용합니다.
(참고로 pooling에는 parameter가 업서용)
이전에는 pooling window의 크기와 stride의 크기가 같아 겹치지 않는 방식이었지만
알렉스넷에서는 overlapping pooling 방식을 사용하였습니다. pooling window의 크기가 stride보다 커
중복되는거죠.
그림처럼 window=3, stride=2이면 1-3,2-4처럼 사이가 겹치게 되죠
전통적인 기법과 비교했을 때, outputsize는 같지만 에러가 더 감소했다고 합니다.
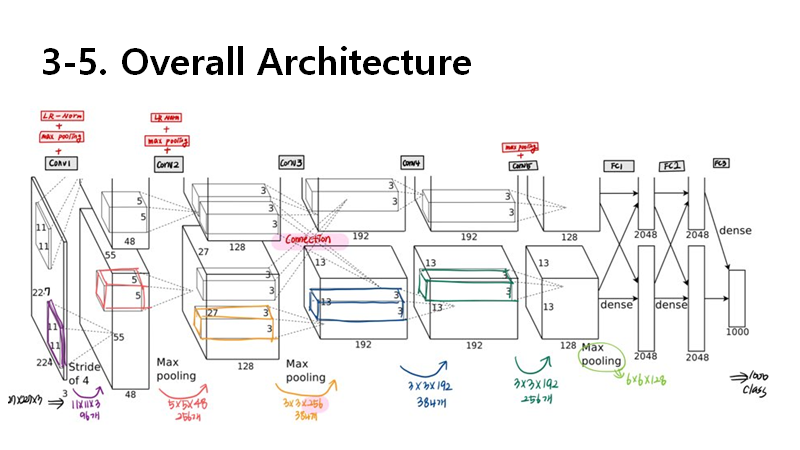
그럼 다시 한번 전체적인 구조도를 봅시다! 제가 직접 그린 손그림입니다 부끄러워요
맨 처음 볼때보다 더욱 친숙해보이기도 하고 어느 layer에 어떤 novel한 (논문에서 말하길) 방식이 쓰였는지 더욱 잘 보일겁니다.
저는 수학전공이지만 수학을 잘 못해 이런 구조들을 볼 떄마다 손으로 직접 하나하나 그리고,쓰고 해야 size를 이해 할 수 있어서 이 이후부터는 layer 별로 feature 의 크기와 파라미터 수를 자세하게 작성할 겁니다.
참고로 input size에 대해서 논문에서는 224로 써있지만, 블로그 같은 곳에서는 227이 맞다는 말이 많네용 ....

써있는 그대로라 설명드릴게 없습니다 핳
conv1,2 layer에 max poolong + normalization 확인할 수 있습니다.

여기서 주목해야할 건 conv3 layer 입니다.
alexnet에서는 gpu 2대를 써서 conv lqyer 중에서는 유일하게 3번째 layer에서만 gpu끼리 connection을 했습니다.
원래 3x3x128 kernel을 썼어야하는데 connection으로 모든 kernel을 다 사용할 수 있어서 3x3x256 kernel을 사용합니다.

다시 보면 전체적인 그림은 이렇게 구성이 됩니다.
오른쪼 그림은 제 발로 그린 구조도 입니다.
왼쪽은 volume size 오른쪽은 kernel size입니다.

4절은 overfitting을 방지하기 위해 어떤 노력들을 했는지 애기하고 있다.
우선 data argumentation 데이터 증강을 했다고 한다.
두 가지 방법 중 첫번째는 이미지 변환과 좌우반전이다.
원래 256x256 사이즈를 마구잡이로 224x224로 crop한다 . 그러면 (256-224)* (256-224) 라서 1024배 증가한다.
그 다음 좌우반전을 하면 이미지가 2배로 늘어나게 된다.
crop과 reflection을 하게 되면 이미지는 총 1024x2 -2048배 증가한다.
하 여기서 보면 인풋 이미지가 224인게 맞는데 너무 헷갈린다 ㅠㅠ
test 시에는 하나의 이미지에 대해 5가지 방식으로 자른 후 좌우반전을 시켜 10개의 patch를 생성해 10개의 sotftmax의 결과값을 평균 내 사용했다고 한다.

색감을 좀 변환했다고 한다.
이걸 image jittering이라고 하는데 rgb값을 막 더해주면 이상해지기 때문에 r,g,b 공분산 매트릭스에서 pca를 통해 중요 성분을 찾아 그만큼 랜덤하게 더해주는 작업이라고 한다.
jittering에도 여러가지가 있는데 오른쪽 그림을 보면 사진이 바뀐 걸 확인할 수 있다.
무슨 카톡이미지보내기 할 때 있는 사진보정?기능들 같당;;
논문에서는 data augmentation을 통해서 overfitting을 막고, top1 error rate를 1% 이상 줄였다고 한다. 오호~

overfitting을 줄이기 위한 방법으로 dropout을 썼다고 합니다.
dropout이란 일정한 확률로 몇몇 neuron에 0을 곱해버리는 작업으로 forward, back 시 영향을 받지 않는다고 합니다.
뉴런들 사이의 의존성을 낮춰서, 특정 뉴런이 나오면 그 옆에 뉴런도 나온다! 같은 co-adaption을 방지합니다.
논문에서는 3개의 fc layer 중에 앞의 2개에만 적용을 하였고, test시에는 output에 0.5를 곱해줬다고 합니다.

실험의 detail 관련된 부분입니다.

실험결과입니다. 당연히 좋으니까 세상에 내놨겠죠 ㅎㅎ
연습용인 ILSVRC-2010에서 좋은 성능을 보였고 , IMAGENET2011FALL 데이터로 pretrain된 모델과 다른 5개의 cnn모델의 평균을 내어 출전한 ILSVRC-2012에서는 2등과 10%가 차이나는 압도적인 결과를 보여주었습니다.

qualitative evaluation에서는 엄청 재미난 얘기가 나옵니다
gpu 두 대에서 각각 kernel이 구하는 특징들이 달랐던 겁니다. gpu1에서는 색감과 관련없는 정보들 gpu2에서는 색감과 관련있는 정보를 구하는 kernel을 사용했다고합니다...
아래에 있는 사진들은 왼쪽에 있는 사진들은 top5 error 사진 8장을 가져온 건데 자기네가 틀릴만했다 그럴싸하지 않냐 라고 하는 사진들입니다 근데 이거 인정;

방금 gpu에 따른 kernel 얘기가 나와서 재밌어서 가져왔습니다. conv에 따라 구하는 feature들이 다 다르네요

참고한 글들입니다.
얼추 아는 내용인데도 불구하고 꽤 많은 시간이 걸린 거 같습니다.
아직 딥러닝 초보자 + 영알못이라서 미숙한 점이 많습니다.
잘못된 부분이나 수정해야할 부분이 있다면 댓글로 알려주세요 😁
👾 ppt는 여기서 다운받으실 수 있습니다
https://www2.slideshare.net/ssuser67be14/alexnet-paper-review
👾자세한 설명과 함께 하고싶으시다면 유튜브로 gogo!
'영어논문 스터디' 카테고리의 다른 글
| SSD (0) | 2021.02.01 |
|---|---|
| YOLO v1 리뷰 (0) | 2021.01.26 |
| Faster RCNN 논문 리뷰 (0) | 2021.01.15 |
| Fast RCNN 논문 리뷰 (0) | 2021.01.09 |
| Attention is all you need 논문 리뷰 (0) | 2020.11.05 |