이 논문을 읽기 전 무조건 rcnn과 sppnet을 공부하고 오면 편하다.
0. Abstract
기존 object detection에서 쓰이던 rcnn이나 sppnet보다 빠른 fast rcnn에 대해 소개한다.
이전 네트워크들에 비해 training, test 속도를 향상시켰고, detection acurracy 또한 높혔다.
이전 rcnn이나 sppnet에 비해 더 빠른 속도와 pascal voc2012에 대해 더 높은 mAP를 보여줬다.
👉 논문에서는 several innovation을 사용해 이런 효과를 볼 수 있었다는데 어떤 것들인지 확인해보자.
1. Introduction
object detection은 단순한 image classification보다는 좀 더 복잡하기에 힘들다.
이런 복잡함 때문에 sppnet , rcnn 등의 네트워크들이 multi-stage pipelines을 통해 모델을 훈련시키는데 이런 방법들은 느리고 세련되지 못했다.
복잡함은 왜 생기냐? 바로 객체의 정확한 localization 때문이다..
- 수많은 객체위치후보 (proposal을 의미)가 생성되어야한다.
- rough한 localization만을 제공하기때문에 정확한 localization을 위해서는 다시 refine되어야한다.
fast rcnn에서는 object proposal을 분류하는 것과 location을 정제하는 것을 동시에 훈련시킬 수 있는 single- stage algorithm을 사용한다.
결과적으로는 rcnn보다 9배 , spp보다 3배 빠르며 PASCAL VOC 2012에 대하여 66% mAP를 보여주었다 .
👉 기존 rcnn, spp와 같은 네트워크들의 단점과 그것을 보안하기 위해 도입한 알고리즘을 얘기하고 있다.
기존엔 정확한 localization을 위해 multi-stage pipelines을 통해 모델을 훈련시켜 느리다는 단점이 있었지만 ,
fast rcnn에서는 이를 합쳐 single stage로 끝내버린다.
1-1. R-CNN and SPPnet
rcnn의 단점을 얘기해보자. 아래 사진만 봐도 오래걸릴 거 같다.
selective search 자체도 빠른 편도 아니고 하나의 이미지에 대해서 2000개의 영역을 뽑아내고 그 영역 각각에 대해 conv net -> svm -> bbox reg를 진행해야한다.

- training이 여러 단계로 이루어진다.
- selective search를 통해 propose된 2000개의 regions들에 대하여 log loss 방식을 사용해 Convnet을 finetune한다
- convnet의 4096개의 피쳐들로 svm을 학습시킨다. 이 때 SVM은 객체를 검출하고, softmax를 대신해 분류한다.
- bounding box regressor를 진행한다. - training에 시간과 비용이 많이 든다.
- svm과 bounding box regreser training을 하며 모든 이미지에 대하여 각각의 proposal에 대해 feature를 뽑아낸다. vgg16같이 깊은 네트워크를 사용한다면 이 과정은 VOC07의 5천장을 학습시키는데 2.5일이 걸리면서 저장공간도 엄청나게 필요로 한다. - object detection가 느리다.
- gpu를 사용하더라도 한 장당 47초가 걸린다.
RCNN은 각각의 object proposal에 대해 연산을 공유하지않고 개별적으로 연산을 진행하기때문에 엄청 느리다.
👉 스터디에서 sppnet 설명을 듣고오니 더욱 이해가 잘 된다.
rcnn은 fc layer의 input size를 맞춰주기 위해 224 x 224로 crop& warp 해준 후 roi마다 conv net을 학습, bbox , svm을 학습해야돼서 시간이 정말 오래 걸린다.
그래서 sppnet에서는 모든 input size에 상관없이 conv를 학습한 후 roi에 대해서 spatial pyranid pooling을 통해 fc layer의 input size를 맞춰준다. 근데 그래봤자 multi-stage다.
rcnn , sppnet모두 한 번에 학습할 수 없기때문에 backpro가 끝까지 진행되지 않아 모든 가중치를 업데이트 시킬수도 없고 느리다.
1.2 Contribution

- rcnn이나 spp보다 mAP가 높다.
- multit task loss를 사용해 single stage로 훈련된다.
- training 시 모든 네트워크 레이어를 업데이트할 수 있다.
- feature caching을 위해 별도의 디스크 저장공간이 필요 없다.
👉 feature caching이 뭐지,,,,? 왜 필요 없지?
+++ 기존 rcnn같은 경우 multi-stage로 이루어져있다. 중간의 svm 학습 때문에
conv net 학습 -> svm 학습 -> bbox regression 학습 이렇게 3가지 단계로 이뤄지기 때문에 각각의 ROI마다의 feature map을 disk에 저장해놓고 bbox나 svm을 학습할 때 가져다 쓴다.
하지만 rcnn은 roi pooling 과 softmax의 사용으로 위 사진처럼 single stage 로 학습이 가능하다. 그렇기 때문에 feature map을 별도로 저장할 필요가 없는 거 같다.
2. Fast R-CNN architecture and training

- 이미지 전체와 object proposals들을 input으로 받는다.
- 네트워크를 통해 전체 이미지는 몇 개의 conv와 max pooling을 거쳐 conv feature map을 생성한다.
- 각각의 object proposal에 대해 RoI pooling layer가 피쳐맵으로부터 길이가 고정된 feature vector를 뽑아낸다.
- 각각의 feature vector는 FC layer를 거쳐 두 개의 output layer로 나눠진다.
- k개의 물체 클래스와 배경으로 즉, k+1개의 class에 대한 softmax 확률추정치에 사용된다.
- 4개의 실수값을 출력해내는데 class에 대한 bounding box positions에 사용된다.
👉 Fast RCNN에 대해 간략하게 설명하고있다.
RCNN과의 가장 차이점은 단순하게 바라보면 convnet을 한 번만 사용한다는 것이다.
RCNN은 2000개의 region에 대해 2000번 네트워크를 거쳤다면 fast rcnn은 한 번만 convnet을 거쳐 피처맵을
만들고 그 피처맵을 계속해서 재사용(?)해 속도가 엄청나게 빨라진다.
이후의 글을 읽기 전 RoI projection부분에 대해서 크게 봤을 때 이해가 잘 안됐는데 한 사진을 보고 이해가 됐다.

전체 이미지에 대해 cnn을 진행해 feature map을 만들어낸다.
그와 동시에 selective search를 통해 전체 이미지 내에서 ROI를 만들어낸다.
이렇게 되면 feature map은 전체 이미지보다 사이즈가 작지만 ROI는 전체 이미지 사이즈에 대해 영역이 잡혀있다.
그렇기 때문에 feature map에 ROI를 projection시켜준다.
rcnn과 크게 달라질 수 있었던 점은 ROI를 프로젝션 한 후 풀링을 통해 고정된 사이즈로 피처를 통일 시켜줬기때문인 거 같다.
라고 이해를 했다! 만약 틀렸다면 댓글로 누군가 남겨줄거라고 믿는다
2.1 The RoI pooling layer
- RoI pooling layer는 RoI 내부의 feature들을 7x7과 같이 고정된 높이Hx너비W 사이즈의 작은 피처맵으로 바꿔준다. 이때의 높이와 너비는 특정 RoI랑은 독립적으로 정해지는 하이퍼파라미터다.
이 논문에서는 rectangular window 사용했다 - 각각의 RoI들은 좌측 상단의 꼭짓점을 나타내는 좌표인 (r,c)와 직사각형의 높이와 너비를 나타내는 (h,w) 4개의 값을 이용해 (r,c,h,w)로 표현된다.
- 피처맵위에 projection 시킨 h x w RoI에 h/H x w/W 크기의 sub-windows로 max-pooling을 진행해 H x W로 만들어준다. pooling은 피쳐맵의 채널들과는 독립적으로 진행된다.
- RoI는 간단하게 보았을 때 spatial pyramid pooling에서 피라미드 레벨이 1인 경우와 같다.
👉 아래 그림처럼 10 x 10 feature map이 있다면 ROI는 10X10에 대해 만들어진 게 아니라 전체 이미지 사이즈에 대해 만들어졌을 것이다.
그렇기 때문에 ROI를 feature map에 대해 projection시켜준다.
그러면 projection된 roi의 사이즈가 h x w 일 때, H x W 크기로 만들어주기 위해 h/H x w/W 크기만큼 grid를 만들고 그에 맞춰 max pooling을 진행한다.
아래 그림 같은 경우 6 x 4 를 2 x 2로 만들기 위해 3x2로 그리드를 나눴고 거기서 가장 큰 값을 뽑는 max pooling을 진행해서 2 x 2로 만들어주었다.
왜 ROI pooling을 거쳐 H x W의 고정된 사이즈인 feature vector로 바꿔주어야할까??
FC layer의 input 크기에 맞추기 위해서이다.
저번 시간에 gap을 공부하면서 fc layer를 사용할 때는 fc의 input size를 맞춰줘야한다는 이슈가 있다는 것을 알았다.
rcnn같은 경우는 crop과 warp를 통해 네트워크의 input size부터 맞춰주었지만, fast rcnn은 네트워크의 input size와는 무관하게 ROI의 size를 H x W로 통일해 FC layer의 input size를 맞춰주었다.

2.2 Initializing from pretrained networks
5개의 max-pooling layer 와 5 ~13개 사이의 conv 를 가지는 3개의 pretrained network로 실험을 했을 경우 fast-rcnn모델을 만들기 위해 3개의 과정을 거쳐야한다.
- 마지막 max pooling layer는 RoI pooling layer로 대체된다.
- 네트워크의 가장 마지막 fc layer와 softmax는 2개의 sibling layer로 대체된다.
하나는 k+1개의 클래스로 분류하는 softmax와 클래스 별 bbox regression - 2가지의 data input을 받는다 : 이미지들과 그 이미지에 대한 RoI들
2.3 Fine-tuning for detection
Fast rcnn의 가장 큰 차이점은 모든 네트워크 가중치를 back-propagation을 통해 업데이트할 수 있다는 것이다.
fast rcnn의 RoI가 너무 크기때문에(때론 이미지 전체일수도 있다.) 기존 sppnet이나 rnn에 적용된 방법을 fast rcnn에 사용하는 것은 비효율적이다. 그래서 다른 방법을 사용했다.
- SGD의 mini-batch를 hieracrchically하게 샘플링했다.
처음 N개의 이미지를 뽑은 후, 각각의 이미지에서 R/N개의 RoI를 뽑아냈다.
이 때, 같은 이미지에서 뽑은 RoI들은 forward, backward 모두 연산과 메모리를 공유한다. - 예를 들어 N = 2 , R = 128 이라면 이미지 하나당 128/2 = 64개의 RoI를 샘플링한다.
RCNN이나 SPPNET에서 사용한 방식인 128개의 이미지에서 ROI를 선택해 학습하는 것보다 훨씬 빠르다. - 이렇게 되면 같은 이미지에서 나온 RoI들끼리 연관이 있어 학습 수렴속도가 느려질 것이라는 우려가 있지만, 실제로 발견되지 않았고 RCNN보다 SGD iteration이 훨씬 적어 좋은 결과를 얻는다.
👉 RCNN이나 SPPNET 같은 경우 mini-batch를 128로 정했을 때, 128개의 서로 다른 이미지로부터 ROI를 무작위로 가져와서 128개의 ROI를 취하는 region-wise sampling 방법을 사용했다고 한다.
이렇게 되면 하나의 배치 안에 서로 다른 이미지에서 온 ROI가 많아져 SPPNET의 학습이 비효율적인 거다.
정말 최악의 경우를 생각해보면 128개의 ROi모두 다른 이미지에서 올 수도 있다.

그래서 FAST RCNN에서는 다른 방법을 사용했는데 이미지를 계층적으로? 하여튼 적은 수의 이미지만 우선 뽑아낸다.
이 논문에서는 2장을 뽑아냈다. 그 후 이미지에서 R/N개씩의 ROI를 추출한다.


2.3.1 Multi-task loss
- fast rcnn은 2개의 output layers를 가지고 있다.
첫번째 layer는 k+1개의 카테고리에 대한 이산확률분포를 말한다. softmax에 의해 p가 계산된다.
두 번째 layer는 bounding box regressor에 대해 출력한다. - training시 RoI에는 ground truth class인 u와 ground truth bounding box regression의 target값인 v가 라벨링된다.
classificattion과 bbox regression를 한 번에 이용해 모델을 학습시키기 위해 multi task loss L을 사용해보자.

- 앞 부분은 classification에 대한 log loss 값이다.
뒷 부분은 Bounding Box Regression에 대한 loss 값이다. - Iverson bracket은 u가 1 이상일 때 1이고, 그 외에는 0으로 나타난다. 이걸 쓴 이유는 background RoI의 경우 ground truth bounding box가 없기 때문에 무시되어야한다. 이 경우 u=0이기에 Iverson bracket을 사용하면 backgroynd인 경우는 무시할 수 있다.
- 이상치의 영향을 덜 받는 L2보다 덜 민감한 L1loss를 사용했다.


- $lambda$는 두 loss 사이의 balance를 조절해주는 하이퍼 파라미터로 실험 내에서는 1로 고정해 사용했다.
👉 처음에는 식을 보고 쫄았는데 그럴 필요 없다. multi loss는 classification을 위한 loss 와 bbox regression을 위한 loss로 구성된다. cls loss는 truth class인 u에 해당하는 확률 p_u에 대해 log loss를 사용한다. -> - log p_u
loc loss는 true box에 대한 offset인 $t^{u}$ 와 예측된 box의 offset v의 차로 L1 loss를 구한다.
2.3.2 Mini-batch sampling
- 위에서 말했던 것과 같이 N=2, R = 128로 SGD mini-batch로 샘플링 했다.
- ground truth bounding box와 IOU가 0.5이상인 RoI 중 25%를 사용했다.
- 0.1 ~ 0.5 사이인 ROI들은 u = 0인 background로 취급했다,
- data augmentation은 0.5의 확률로 수직반전을 한 것 외에는 없다.
2.3.3 Back-propagation through RoI pooling layers

- $x_{i}$: 피처맵의 인덱스가 i인 곳 , r : r번째 RoI , J : RoI pooling의 아웃풋의 인덱스가 j인 곳
- i*(r, j) : sub-window내 에서 xi값이 제일 큰 인덱스
👉 수식만 보면 이해가 잘 안 간다. 그림이랑 같이 봤다.
backpropagation을 할 때, i가 포함된 subwindow 내에서 Xi값이 제일 커서 pooling으로 값이 뽑힌 i만 loss에 영향을 줄 수 있다.
아래 녹색ROI의 경우 0번째 ROI라서 r=0 , 주황색 ROI의 경우 r =1이다.
feature map에서 x_23에 해당하는 부분이 녹색roi , 주황색 roi의 sub-window내에서 가장 큰 값이라 pooling 시 뽑힌다.
그렇기 때문에 주황색 기준 1번째 ROI에서 0번째 sub-window의 값이 x_23이므로 i*(1,0) =23이 되는거다.
여러 ROI가 $x_{i}$ 를 포함하고 있으면서 각각의 subwindow내에서 x_i가 가장 큰 값일 수 있기때문에 합을 생각해준다.
그래서 백프로파게이션 식이 저렇게 나오게 되는 거다. 그렇기 때문에 모든 네트워크를 학습시킬 수 있게 된다.
자세하게 완전히 이해하지는 못했지만 대략적인 감은 잡을 수 있었다.

2.3.4 SGD hyper-parameters
- softmax classfication, bbox regression의 FC 레이어는 각각 표준편차가 0.01 , 0.001이며 평균이 0인 가우시안 분포에서 초기화해주었다.
- bias는 0으로 초기화해주었다.
- 모든 layer의 가중치의 learning rate는 1 , bias는 2를 사용했으며 global learning rate = 0.001
- momentum = 0.9 , weight decay = 0.0005 사용
👉 아래 그림의 노랗게 칠한 부분의 FC 각각을 초기화 해준 것을 얘기하고 있다.

global learning rate가 뭘까?? 스터디원의 뇌피셜로는 saturated 해질때마다 learning rate에 곱해주는 값을 얘기하는 것 같다는데 정확히 잘 모르겠다.
2.4 Scale invariance
scale invariant하게 객체를 탐지하는 법에는 2가지가 있다.
brute force (single -scale) : traning , test 시에 미리 정해놓은 픽셀 사이즈에 대해 전처리 된다.
image pyramids (multi-sclae) : 여러 scale에 대해서 random하게 진행된다.
👉 저번주 스터디에서 SIFT에 대해 설명했었는데 주의 깊게 안들었더니,,,
scale invariance는 (뇌피셜) 사이즈가 변하거나, 데이터가 회전되어도 변하지 않는? 불변하는 이 이미지만의 특징이라고 알고 있다. 이전 vgg에서 비슷한 걸 봤던 거 같은데 single scale만 사용하는 방식과 multi-scale을 사용한는 방식 이렇게 두가지 있는데 sppnet같은 경우가 multi - scale을 사용한다. 뒤에서 나오겠찌만 이 글에서는 single을 사용한다.
SIFT에 대해서 좀 더 공부가 필요한 듯하다.
3. Fast R-CNN detection
각각 test ROI r에 대해 클래스에 해당하는 $p_{k}$값과 bounding box offset이 출력된다.
이를 이용해 클래스와는 독립적으로 NMS를 실행한다.
3.1. Truncated SVD for faster detection
👉 아 선형대수학의 필요성을 정말 절실히 깨달았던 논문,,,, 수학전공인데도 SVD가 생각이 안난다.
Truncated SVD 를 사용해서 연산의 수가 줄어들었기에 속도가 엄청 빨라졌다 이거만 알아도 된다.
간략하게 이해한 걸 써보면 각각의 ROI에 대해 FC연산이 엄청나게 많이 든다. fc의 cost를 줄일 수 있는 방법에 대해서 truncated SVD를 얘기하고 있다.

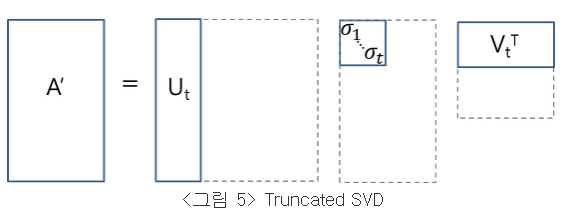
만약 FC layer의 weight matrix W가 u x v였다면 파라미터 연산을 u * v 번 해야했을 것이다.
하지만 truncated SVD를 사용하면 t * (u + v) 번만 하면 되기 때문에 t가 u,v 보다 작을 때 아주 큰 효과를 볼 수 있다.

내가 논문을 제대로 이해한 게 맞는진 모르겠지만 원래 하나의 FC의 weight matrix 가 W였다면 , 이걸 위 사진의 형광색 부분처럼 두 개의 fc로 나눈다.
이후 첫번째 layer에서는 bias없이 $Sigma _{t}$ º Vt 를 weight matrix로 가진다.
이후 activation fuction 없이 두번째 layer에서는 원래 W가 가지고 있던 bias를 가지면서 U를 weight matrix로 가진다
그럼 두 FC레이어를 거치게 되면 결국 위에 써있는 식(truncated SVD)을 거친것과 같아진다.
논문 6쪽을 보면 top 1024 singular values from the 25088 x 4096 matrix in VGG16’s fc6 layer and the top 256
singular values from the 4096 x 4096 fc7 layer 라는 얘기가 나온다. 하나만 예를 들어보자.
FC6인 경우 첫번째 fc layer의 weight matrix는 t = 1024이므로 $Sigma $ X Vt라서 1024 * 4096이다.
두 번째 layer의 경우 weight maxtrix는 t = 1024 , U 라서 25088 * 1024가 된다.
만약 FC6을 두 개로 쪼개지 않았다면 25088 * 4096 번 해야할 것을 1024 * (4096 + 25088) 번만 연산하면 된다.

4. Main results
- VOC07,2010,2012에서 Sota maP 경신
- 빠른 training, testing 속도
- VGG16의 conv layer를 fine tunning 했더니 mAP 상승
4.1. Experimental setup
pretrained 된 모델을 3가지 사용해 실험해본다.
- Caffenet (S)
- VGG CNN M 1024 (M)
- VGG16 (L)
- single scale training , testing 사용
4.2~3 VOC results
여긴 안읽었다. 뭐 성능이 좋아졌으니까 논문을 쓰고 유명해졌겠지,,,, 자기들 자랑하는 거까지 굳이 보고싶지않다.
4.4. Training and testing time
- Truncated SVD 를 사용하여 rcnn , sppnet보다 훨씬 빨라졌다.
- feature caching 을 하지 않아 별도의 저장공간도 필요하지 않다.

4.4.1 Truncated SVD
- svd를 적용했더니 mAP가 0.3포인트밖에 안떨어졌지만 속도는 30% 이상 줄어들었다.

4.5. Which layers to fine-tune?

- fc layer만 fine tunning하면 오히려 sppnet이 더 성능이 좋음 .
- rcnn에서는 fc만 fine tunning하는 것이 오히려 좋지 않음
- vgg16d의 경우 conv2_1부터 fine tunning을 했을 경우 mAP는 0.3 증가했지만 1.3배 더 시간이 오래걸렸다.
- 그렇기 때문에 conv3_1부터(S,M은 conv2부터) fine - tunning을 하고 이전은 freeze시킨다.
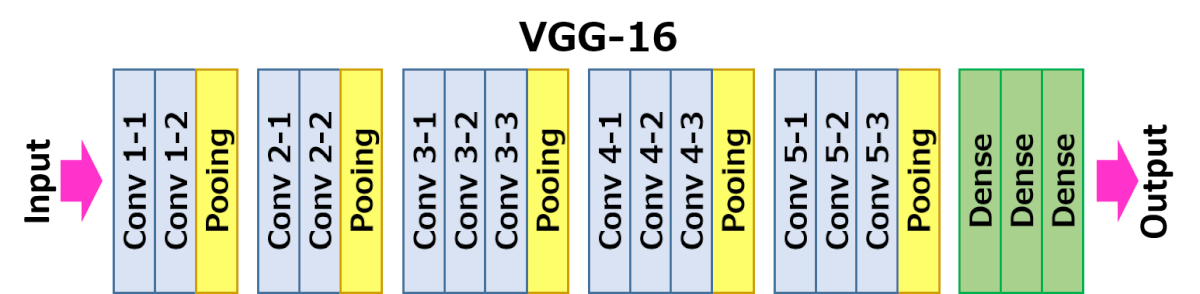
5. Design evaluation
5.1. Does multi-task training help? ㅇㅇ multi-task 이용시 mAP가 더 높게 나옴
5.2. Scale invariance: to brute force or finesse? multi scale 사용시 더 성능이 좋지만 single scale과 크게 차이 나지 않고, 메모리나 시간이 더 걸리기에 그냥 scale 씀
5.3. Do we need more training data? 데이터가 많으면 많을수록 mAP가 향상됨
5.4. Do SVMs outperform softmax? vgg16(L)에 대하여 svm보다 softmax 사용시 0.1 ej shvdma
5.5 Are more proposals always better? proposal이 너무 많으면 성능 저하

나만의 정리
- ROI pooling으로 input size에 무관하게 모델에 input 할 수 있다. backpropagation이 가능해져 모든 네트워크의 가중치가 업데이트 될 수 있다.
- softmax , multi-task loss 의 사용으로 single stage , end-to-end가 가능해졌다.
- hieracrchical sampling을 통해 mini -batch 내에서 feature 끼리의 공유가 가능해졌다.
- svd를 통해 ROI마다 학습해야되는 fc layer의 cost를 감소시킬 수 있었다.
아 정말 선형대수학의 필요성을 절실히 깨달은 논문이었다. 여태까지 읽었던 논문 중에 수식이 제일 많았던 거 같다.
fast rcnn은 ROI라는 개념 하나로 정말 많은 것을 바꿨다. 하지만 selective search라는 알고리즘을 통해 region proposal이 진행되고 있는데 딥러닝도 아니고 느리다. 그래서 region proposal도 딥러닝으로 하면 어떨까? 라는 생각에서 착안돼 PRN이라는 개념과 함께 그 이후의 faster rcnn이 나오게 된다. 그래서 다음 주 논문은 faster rcnn이다. 지금 생각해보면 맨 처음 읽었던 영어 논문이 FASTER RCNN인데 그 때랑 지금 얼마나 많이 달라졌고, 얼마나 더 많이 이해하는지 비교해보는 재미가 쏠쏠할 거 같다ㅎㅎ
참고자료
blog.naver.com/laonple/220776743537
www.robots.ox.ac.uk/~tvg/publications/talks/fast-rcnn-slides.pdf
github.com/hwkim94/hwkim94.github.io/wiki/Fast-R-CNN(2015)
darkpgmr.tistory.com/106 -> SVD
아직 딥러닝 초보자 + 영알못이라서 미숙한 점이 많습니다.
잘못된 부분이나 수정해야할 부분이 있다면 댓글로 알려주세요 😁
👾 논문 확인 arxiv.org/pdf/1504.08083.pdf
👾 자세한 설명은 유튜브로 gogo~! youtu.be/0u_v7p_k6iQ
'영어논문 스터디' 카테고리의 다른 글
| SSD (0) | 2021.02.01 |
|---|---|
| YOLO v1 리뷰 (0) | 2021.01.26 |
| Faster RCNN 논문 리뷰 (0) | 2021.01.15 |
| Alexnet 논문 리뷰 - ppt (0) | 2020.11.17 |
| Attention is all you need 논문 리뷰 (0) | 2020.11.05 |