numpy
- list에 비해 빠르고, 메모리 효율적
- 반복문 없이 데이터 배열에 대한 처리를 지원
- C,C++ 등의 언어와 통합 가능
📌 ndarray
- np.array 함수를 활용해 배열을 생성 → ndarray
- 하나의 데이터 type만 배열에 넣을 수 있음 (C같이)
- List와 가장 큰 차이점 -> 다이나믹 타이핑 x (그래서 빠름 )
- C의 Array를 사용하여 배열을 생성함
test_array = np.array(["1","4",5.0 ,8] , float)
test_array
>> array([1., 4., 5., 8.])a = [1,2,3,4,5]
b = [5,4,3,2,1]
a[0] is b[4]
>>True
a = np.array(a)
b = np.array(b)
a[0] is b[4]
>>False
- shape : dimension 구성 반환 → tuple 타입으로 반환해줌
- ndim : dimension의 수 (shape을 반환하는 tuple의 길이)
- size : data의 개수 (shape의 수를 다 곱한 값과 동일)
- dtype : data type 반환
- 각 element가 차지하는 memory의 크기가 결정됨 (동적타이핑x)
- nbytes : ndarray object의 메모리 크기를 반환함
np.array([[1,2,3] , [4.5 , "5" , "6"]] , dtype = np.float64).nbytes
>> 48
- reshape : shape의 크기를 변경 but element의 갯수는 동일 (즉, size가 같아야함)
- "-1" 사용시 size에 맞춰 알아서 reshape 해줌
- 만약 원소가 4개인데 3으로 reshape 3 해줄 경우, 에러가 난다.

- np.flatten : reshape의 일종 , reshape(1,-1)과 동일

📌indexing _slicinng ✨
- 이차원 배열의 경우 array[r,c]로 접근 가능
- 모든 행을 추출할 때와 열을 추출할 때 다르다. 모든 열을 추출하고싶으면 무조건 행 부분을 : 로 처리해줘야함



-
arange : array 값의 범위를 지정하여, 값의 list 를 생성하는 명령어
- 시작 , 끝 , step 사용 가능 , float 범위로 쪼갤 수 있음

-
empty : shape만 주어지고 비어있는 ndarray 생성 -> memory initialization 되지 않음 쓰레기 값이 남아있을 수도 있다.
-
zeros_like (ones_like) : 기존 ndarray의 shape 크기만큼 0(1) 로 이뤄진 array를 반환
-
identity : 단위 행렬 생성
- 행의 개수를 인자로 주면 nxn의 단위행렬 생성

-
eye : 대각선이 1인 행렬
- identity와 다르게 대각선의 시작 인덱스를 정해줄 수 있음 !

-
diag : 대각 행렬의 값 추출 (!! 생성하는 게 아니라 이미 있는 행렬의 대각선에 있는 값만 출력)
- eye처럼 추출해 줄 대각행렬의 시작 인덱스를 정해줄 수 있음
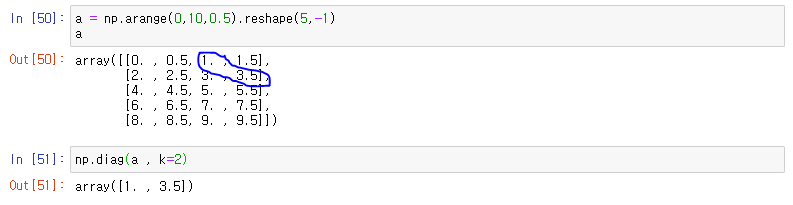
-
random sampling : 데이터 분포에 따른 sampling으로 array 생성
- 아래 코드는 평균이 0 , 표준편차가 1인 정규분포에서 10개를 랜덤으로 추출해 2,5크기로 reshape

📌 operation fuctions
✨👀 axis

차원이 증가하면서 axis가 하나씩 밀린다. 즉, rank가 추가되면 그 rank의 axis = 0 나머지는 1씩 증가
-
sum
- axis를 기준으로 sum 가능

- concatenate (중요)
-
vstack , hstack : 가장 기본
-

-
concatenate : "axis" 를 기준으로 합침


❗ np.newaxis : 새로운 축 추가

📌 array operation
-
element - wise : array간 shape 가 같다면 같은 위치에 있는 값들끼리 연산이 일어남
-
dot-product
-
.transpose or .T : 전치행렬
-
broadcasting : array간 shape이 다를 때


❗ for loop < list comprehension < numpy로 속도가 빠름
📌 comparisions
- a가 broadcastiong 이 일어나 각각 element-wise하게 비교함

-
all & any : 모두 혹은 하나라도 True 면 True 반환
- 배열간의 크기가 동일할 때 element 간 비교의 결과를 boolean type으로 반환
- logical_and , logical_not , logical_or 등 존재
- np.where 사용법
1) np.where(조건문, 참일 때 , 거짓일 때) : 조건문을 만족시키면 참인 값으로, 아니라면 거짓값으로 재할당해줌

2) np.where(조건문) : 조건문을 만족시키는 인덱스들을 array로 반환해줌

-
argmax & argmin : array 내 최대 혹은 최소값의 "index"를 반환
-
argsort : 가장 작은 값을 가지는 "인덱스"부터 가장 큰 값을 가지는 "인덱스"를 array로 반환
📌 boolean & fancy index
-
fancy index : array를 index value 로 사용해서 값 추출

📌 numpy data i/o
- loadtext : 파일 호출
- savetext (파일명 , type)
- 보통 npy 파일로 저장 pickle 형태
벡터와 행렬
📌 행렬의 곱셈과 내적
-
행렬 곱셈 : i번째 행벡터와 j번째 열벡터 사이의 내적을 성분으로 가지는 행렬 계산
- @ 연산을 사용한다.
-
행렬 내적 (np.inner) : 같은 인덱스에 대해서 element-wise하게 곱셈이 일어난다.
- 우리가 흔히 알고있는 행렬의 곱(열 x 행)과는 다르다. 주의
📌 행렬을 바라보는 관점
- x_ij : i번째 데이터의 j번째 변수의 값
-
벡터공간에서 사용되는 연산자 Rm -> Rn
- m차원에서 n차원으로의 선형변환 , 패턴 추출 , 데이터 압축에 사용
📌 유사 역행렬
-
역행렬
- 정방행렬이며 행렬식이 0이 아니어야된다. -
유사 역행렬
- 역행렬을 계산할 수 없는 상황에서 유사역행렬(pseudo0-inverse)을 사용한다. -
n>=m일 경우 , $A^{+}$ = $(A^{T}A)^{-1}$$A^{T}$
📌 Lab1 : 연립방정식 풀기
-> 식으로만 나와있고, 직접 구현해볼 수 있는 예제가 없어서 검색을 통해 적당한 예제를 찾았다.

A = np.array([[-1,2] , [2,3] ,[2,-1]])
B = np.array([[0,],[7,],[5,]])
print(A.shape)
print(B.shape)
>> (3,2)
>> (3,1)plus_A = np.linalg.pinv(A)
x = plus_A @ B
x
>> array([[2.49180328],
[0.78688525]])X = np.linalg.inv(A.T @ A) @ A.T
X = X @ B
X
>> array([[2.49180328],
[0.78688525]])np.linalg.pinv를 사용하면 정방행렬이 아닌 연립방정식의 해를 구할 수 있다.
1번 코드는 np.linalg.pinv를 사용해 x의 값을 구한 코드
2번 코드는 pinv 를 사용하지 않고, 직접 구현한 코드
📌 Lab2 : 선형회귀분석
sklearn의 LinearRegression 사용
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X,y)
y_test = model.predict(x_new)
y_test
>> array([[-111.94615175],
[ -63.99001926],
[ -16.03388677],
[ 31.92224573],
[ 79.87837822],
[ 127.83451071],
[ 175.7906432 ],
[ 223.7467757 ],
[ 271.70290819],
[ 319.65904068]])직접 유사역행렬을 사용하여 구현
beta = np.linalg.pinv(X) @ y
y_test = x_new @ beta
y_test
>> array([[-242.6141249 ],
[-187.66483013],
[-132.71553535],
[ -77.76624058],
[ -22.81694581],
[ 32.13234897],
[ 87.08164374],
[ 142.03093852],
[ 196.98023329],
[ 251.92952806]])왜 출력값이 다를까?
선형회귀분석에는 y절편 즉 상수항이 포함되어야한다.
X_ = np.array([np.append(x,[1])for x in X])
print(X_.shape)
X_new = np.array([np.append(x, [1]) for x in x_new])
print(X_new.shape)
beta = np.linalg.pinv(X_) @ y
print(beta.shape)
y_test = X_new @ beta
y_test
>> array([[-111.94615175],
[ -63.99001926],
[ -16.03388677],
[ 31.92224573],
[ 79.87837822],
[ 127.83451071],
[ 175.7906432 ],
[ 223.7467757 ],
[ 271.70290819],
[ 319.65904068]])
벡터,행렬 들 기존에 잘 알고있던 것들이라 편한 마음으로 수업을 들으려고 했는데,
뒤쪽에 유사역행렬이 나와서 잔뜩 긴장하고 들었다. 막히는 부분이 있었는데 애드위드 게시판에 잘 정리가 되어있는 걸 보고 학습게시판의 소중함을 느낀 하루였다.
또 선대공부와 이를 numpy 등으로 표현하는 공부가 더 필요하다고 느꼈다. 이건 어떻게 공부해야되나 싶다,,,
오늘의 한 줄 : 코딩+선형대수 둘 다 잘해야된다.
피어세션
이번 주 피어세션에서는 하루에 2문제씩 알고리즘 문제 풀이를 진행하기로 했다.
1일차인만큼 가볍게 bfs & dfs로 진행
다 풀어봤던 문제들이지만 파이썬으로 풀려니 또 새롭긴하다.
- 나이트의 이동 (자세한 풀이 : blahblahlab.tistory.com/23)
from collections import deque
dx = [1,1,-1,-1,2,2,-2,-2]
dy = [2,-2,2,-2,1,-1,1,-1]
def bfs(start_x , start_y , target_x , target_y, l):
visited = [[0 for _ in range(l)]for _ in range(l)]
q = deque([[start_x, start_y]])
visited[start_x][start_y] = 1
while q :
x , y = q.popleft()
if x == target_x and y == target_y:
return visited[target_x][target_y]-1
for i in range(8) :
nx = x + dx[i]
ny = y + dy[i]
if 0 <= nx < l and 0 <= ny <l and visited[nx][ny] ==0 :
visited[nx][ny] = visited[x][y] + 1
q.append([nx,ny])
tc = int(input())
while tc :
l = int(input())
cur_x , cur_y = map(int,input().split())
target_x , target_y = map(int,input().split())
print(bfs(cur_x ,cur_y , target_x ,target_y ,l))
tc -= 1- 유기농배추( 자세한 풀이 : blahblahlab.tistory.com/59)
from collections import deque
dx = [-1,1,0,0]
dy = [0,0,-1,1]
def bfs(s_x,s_y,n,m,ground):
q = deque([[s_x ,s_y]])
ground[s_x][s_y] = 0
while q:
x, y = q.popleft()
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if 0 <= nx < n and 0 <= ny < m and ground[nx][ny] :
q.append([nx,ny])
ground[nx][ny] = 0
tc = int(input())
for _ in range(tc) :
m,n,k = map(int, input().split())
ground =[[0 for _ in range(m)]for _ in range(n)]
for _ in range(k):
x, y = map(int,input().split())
ground[y][x] = 1
cnt = 0
for i in range(n):
for j in range(m):
if ground[i][j]:
bfs(i,j,n,m,ground)
cnt += 1
print(cnt)'Naver Ai Boostcamp' 카테고리의 다른 글
| [DAY 8] Pandas I / 딥러닝 학습방법 이해하기 (0) | 2021.01.27 |
|---|---|
| [DAY 7] 경사하강법 (0) | 2021.01.26 |
| [DAY 5] 파이썬으로 데이터 다루기 (0) | 2021.01.23 |
| [DAY 4] 파이썬 기초 문법 III (1) | 2021.01.21 |
| [DAY 3] 파이썬 기초 문법 II (0) | 2021.01.20 |