📌 학습 목표
1. 강의 절반 듣기
2. DeconvNet , SegNet 구현해보기
📌 학습 정리
1. FCN의 한계점
1. 객체의 크기가 너무 크거나 작은 경우 예측을 잘 못한다.
- 3x3 같은 미리 정의된 conv를 사용하기 때문에 전체적인 context를 보는 게 아니라 local한 정보들만으로 예측을 하게 된다. ex) 버스 창에 비친 자전거를 인식
2. Object의 디테일한 부분이 사라지는 문제가 발생한다.
-Deconv 절차가 너무 간단하기 때문
2. Decoder를 개선한 models
Deconv의 절차가 너무 간단해 디테일한 부분을 잡아내지 못하는 FCN의 한계점을 극복하기 위해 모델을 Encoder , Decoder 부분으로 나누어 Decoder 부분을 더욱 효과적으로 학습함
2.1 DeconvNet
- Deconder를 Encoder와 대칭으로 만든 형태 ( MaxPooling - UnPooling , Conv - Deconv)
- Unpooling이 하는 역할
- Unpooling은 디테일한 경계를 포착하고 , Transposed Convolution은 전반적인 모습을 포착한다.
- Maxpooling을 할 때, 최댓값의 indices를 저장해서 넘겨준다. Unpooling 시 전달받은 indices에 맞춰 값을 넣어주고, 나머지는 다 0으로 채워주게 된다.
- 이런 식으로 Sparse하지만 중요한 경계 특징을 잘 잡아낸다. (자전거 사진 넘나리 신기).
-> sparse한 부분은 Transposed conv가 메꿔주자! - pooling의 경우 정보가 손실되는 문제점이 있는데 unpooling을 통해서 정보를 복원할 수 있다.

- Transposed conv가 하는 역할
- input object의 모양을 복원
- Unpooling이 만들어놓은 sparse한 부분들을 메꿔준다.
- 얕은 층의 경우 global feature들을 , 깊은 층의 경우 local feature들을 잡아낸다.
- Unpooling과 Transposed
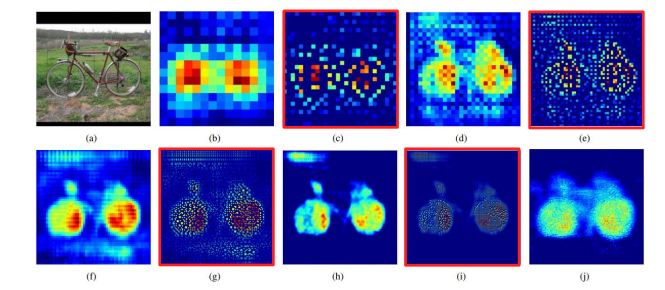
한 줄 요약 : Unpooling이 메꿔주고 , TransposedConv가 채워준다. (웹툰 초안 그려놓으면 어시가 색칠하는 넉낌)
'''
reference
http://cvlab.postech.ac.kr/research/deconvnet/model/DeconvNet/DeconvNet_inference_deploy.prototxt
'''
import torch
import torch.nn as nn
from torchvision import models
class DeconvNet(nn.Module):
def __init__(self, num_classes=21):
super(DeconvNet, self).__init__()
self.dropout = nn.Dropout2d()
self.pool = nn.MaxPool2d(kernel_size = 2, stride = 2, return_indices = True) # unpooling을 위함
self.unpool = nn.MaxUnpool2d(kernel_size = 2, stride = 2) # unpooling을 위함
self.conv1 = self.make_CB(2,3,64)
self.conv2 = self.make_CB(2,64,128)
self.conv3 = self.make_CB(3,128,256)
self.conv4 = self.make_CB(3,256,512)
self.conv5 = self.make_CB(3,512,512)
self.conv_7x7 = nn.Conv2d(512, 4096, 7)
self.conv_1x1 = nn.Conv2d(4096, 4096, 1)
self.deconv_7x7 = nn.ConvTranspose2d(4096, 512, 7)
self.deconv5 = self.make_DB(3,512,512)
self.deconv4 = self.make_DB(3,512,256)
self.deconv3 = self.make_DB(3,256,128)
self.deconv2 = self.make_DB(2,128,64)
self.deconv1 = self.make_DB(2,64,64)
self.score = nn.Conv2d(64,num_classes,1)
def forward(self, x):
x = self.conv1(x)
x , pool1 = self.pool(x)
x = self.conv2(x)
x , pool2 = self.pool(x)
x = self.conv3(x)
x , pool3 = self.pool(x)
x = self.conv4(x)
x , pool4 = self.pool(x)
x = self.conv5(x)
x , pool5 = self.pool(x)
x = self.conv_7x7(x)
x = self.dropout(x)
x = self.conv_1x1(x)
x = self.dropout(x)
x = self.deconv_7x7(x)
x = self.unpool(x ,pool5)
x = self.deconv5(x)
x = self.unpool(x ,pool4)
x = self.deconv4(x)
x = self.unpool(x ,pool3)
x = self.deconv3(x)
x = self.unpool(x ,pool2)
x = self.deconv2(x)
x = self.unpool(x ,pool1)
x = self.deconv1(x)
x = self.score(x)
return x
def make_DB(self, repeat, in_channels , out_channels, kernel_size = 3 , stride = 1 , padding = 1):
layers = []
for i in range(repeat):
if (i==repeat-1):
layers.append(nn.ConvTranspose2d(in_channels, out_channels,kernel_size, stride = stride , padding = padding))
layers.append(nn.BatchNorm2d(out_channels))
else :
layers.append(nn.ConvTranspose2d(in_channels, in_channels,kernel_size, stride = stride , padding = padding))
layers.append(nn.BatchNorm2d(in_channels))
layers.append(nn.ReLU(True))
return nn.Sequential(*layers)
def make_CB(self, repeat, in_channels , out_channels, kernel_size = 3 , stride = 1 , padding = 1):
layers = []
for i in range(repeat):
if (i == 0):
layers.append(nn.Conv2d(in_channels, out_channels,kernel_size, stride = stride , padding = padding))
else :
layers.append(nn.Conv2d(out_channels, out_channels,kernel_size, stride = stride , padding = padding))
layers.append(nn.BatchNorm2d(out_channels))
layers.append(nn.ReLU(True))
return nn.Sequential(*layers)
2.2 SegNet
- 성능보다는 속도에 초점을 맞춘 모델 => Road Scene Understanding applications 분야 (자율주행에서는 아무리 성능이 좋아도 느리면 무용지물)
- Decoder부분에서 Convolution을 이용했다.
- 속도를 올리기 위해 중간 FC layer를 모두 제거해서 파라미터를 감소했다.
- score는 3x3 conv (속도를 내기 위해 중간 layer는 제거 해놓고 굳이 3x3을 하는 이유는? 질문을 했더니 마스터님께서 github에 질문을 주셨다고 한다. 나도 앞으로 그렇게 해보자)
import torch
import torch.nn as nn
from torchvision import models
class SegNet(nn.Module):
def __init__(self, num_classes=12, init_weights=True):
super(SegNet, self).__init__()
backbone = models.vgg16_bn(pretrained = True)
self.enc_conv1 = nn.Sequential(*list(backbone.features.children())[0:4])
self.enc_conv2 = nn.Sequential(*list(backbone.features.children())[7:13])
self.enc_conv3 = nn.Sequential(*list(backbone.features.children())[14:23])
self.enc_conv4 = nn.Sequential(*list(backbone.features.children())[24:33])
self.enc_conv5 = nn.Sequential(*list(backbone.features.children())[34:43])
self.pool = nn.MaxPool2d(kernel_size = 2, stride = 2 , return_indices = True)
self.dec_conv5 = self.make_CB(3, 512, 512)
self.dec_conv4 = self.make_CB(3, 512, 256)
self.dec_conv3 = self.make_CB(3, 256, 128)
self.dec_conv2 = self.make_CB(2, 128, 64)
self.dec_conv1 = self.make_CB(1, 64, 64)
self.unpool = nn.MaxUnpool2d(kernel_size = 2, stride = 2 )
self.score = nn.Conv2d(64, num_classes, kernel_size =3 , stride = 1, padding = 1)
def forward(self, x):
x = self.enc_conv1(x)
x , pool1 = self.pool(x)
x = self.enc_conv2(x)
x , pool2 = self.pool(x)
x = self.enc_conv3(x)
x , pool3 = self.pool(x)
x = self.enc_conv4(x)
x , pool4 = self.pool(x)
x = self.enc_conv5(x)
x , pool5 = self.pool(x)
x = self.unpool(x , pool5)
x = self.dec_conv5(x)
x = self.unpool(x , pool4)
x = self.dec_conv4(x)
x = self.unpool(x , pool3)
x = self.dec_conv3(x)
x = self.unpool(x , pool2)
x = self.dec_conv2(x)
x = self.unpool(x , pool1)
x = self.dec_conv1(x)
x = self.score(x)
return x
def make_CB(self, repeat, in_channels , out_channels, kernel_size = 3 , stride = 1 , padding = 1):
layers = []
for i in range(repeat):
if (i == repeat-1):
layers.append(nn.Conv2d(in_channels, out_channels,kernel_size, stride = stride , padding = padding))
layers.append(nn.BatchNorm2d(out_channels))
else :
layers.append(nn.Conv2d(in_channels, in_channels,kernel_size, stride = stride , padding = padding))
layers.append(nn.BatchNorm2d(in_channels))
layers.append(nn.ReLU(True))
return nn.Sequential(*layers)파라미터 수가 얼마나 차이난다고 중간 FC들(7X7 , 1X1 , 7X7) 을 다 삭제한 걸까?
DeconvNet과 동일하게 추가해주어보았다.
##
self.conv_7x7 = nn.Conv2d(512, 4096, 7)
self.conv_1x1 = nn.Conv2d(4096, 4096, 1)
self.deconv_7x7 = nn.ConvTranspose2d(4096, 512, 7)[추가하기 전 ]

[추가한 후]

처음에는 잘 못 보고 ?더 적은데? 싶었지만 뒤에 0이 하나 더 붙는다 하하하,, 대략 8배 정도 차이가 나게 된다.
중간 FC가 4096까지 늘려서 그런 거같다. (4096까지 늘리는 이유는 vgg를 따라하기 위해서)
여기서 궁금한 점은 속도를 줄이겠다고, 중간을 싹 날린 SegNet에서 왜 score는 3x3으로 구했는지이다.
1x1로 하면 연산량을 score기준 1/9로 줄일 수 있을텐데,,,
실제로도 inference를 하면 11초 정도 차이가 난다고 한다.
-> 이 부분을 마스터님께 질문드렸더니 논문 저자 github에 질문을 해보셨다고 한다. 와웅 그런 방법도 있구나 나도 앞으로 써봐야겠다.

3. Skip connection을 적용한 모델
3-1. FC DenseNet
- 어마어마한 녀석이다. skip connection이 총 3번 들어가게 된다.
- Dense Block내 에서의 skip connection(이 때는 channel을 concate해주는 식이다)
- Desne Block 이전과 Dense Block 이후로의 skip connection
- Encoder 부분에서 Deconder 부분으로 가는 Skip connection
- 구현해보고 싶은데 약간 무섭다.
구현 하려면 channel이 늘어나는 비율을 알아야한다. 시간나면 논문보고 구현해보자. 엄청난 경험이 될 거 같다.

3-2 Unet
- Unet은 짧게 설명해주셨다. 목요일 수업에서 다룰 예정이어서 같다.
나머지 4장부터는 내일다시-
📌 피어세션
오늘 강의 진국이다; 진짜 좋다 MRC, DST 하는 사람들한테도 추천해주고 싶을 만큼 좋은 거 같다. 그니까 아껴들어야지
오늘 피어세션에서 모르는 거 질문을 했더니 순간 Ustage로 돌아온 기분이 약간 들었다. 마스터님께 질문을 드렸는데 너무 귀찮게 해드린 건 아닌가 약간 죄송한 마음 ;ㅂ;. but 모르는 게 있으면 github에 질문을 남긴다니,,,! 나도 써먹어야지
오늘 피어세션 시간에 처음으로 PR 날리는 법을 보냈다. 롤백, 브런치 ,머지 처음 들어보는 단어가 너무 많지만 유지님한테 열심히 배울 예정
오늘의 알고리즘 시간에는 2019 카카오 인턴십 1,2 번 문제
programmers.co.kr/learn/courses/30/lessons/64061
코딩테스트 연습 - 크레인 인형뽑기 게임
[[0,0,0,0,0],[0,0,1,0,3],[0,2,5,0,1],[4,2,4,4,2],[3,5,1,3,1]] [1,5,3,5,1,2,1,4] 4
programmers.co.kr
programmers.co.kr/learn/courses/30/lessons/64065
코딩테스트 연습 - 튜플
"{{2},{2,1},{2,1,3},{2,1,3,4}}" [2, 1, 3, 4] "{{1,2,3},{2,1},{1,2,4,3},{2}}" [2, 1, 3, 4] "{{4,2,3},{3},{2,3,4,1},{2,3}}" [3, 2, 4, 1]
programmers.co.kr
두 문제 합쳐서 50분 정도 걸렸다.
2번 문제가 문자열 문자였는데 "[1,2,3]"이 있으면 ""도 input인 줄 알았는데 훼이크였다;; 여기서 시간을 너무 많이 잡아먹었다.
3번 문제도 도전했다가 처참히 실패! 핑계를 대자면 c++로 문자열을 다루기 너무 힘들다. 파이썬 체고!
새벽 2시 30분이지만 ^^,,,, 메타러닝 머시기 논문이랑 SETR논문 읽어야한다.
'Naver Ai Boostcamp' 카테고리의 다른 글
| Day4 ] (0) | 2021.04.30 |
|---|---|
| Pstage3_Day3 ] (0) | 2021.04.29 |
| Pstage3_Day1 ] Semantic Segmentation의 기초와 이해 (0) | 2021.04.26 |
| [4/15] BERT 언어 모델 (2) + 나만의 BERT 만들기 (0) | 2021.04.16 |
| [04/14] BERT 언어 모델 (1) (0) | 2021.04.14 |